So you’re not content with the 99.9% uptime that you get from your premium hosting provider? Well that’s 8h 45m 56s of downtime per year so I guess I can understand that. For a lot of providers 99.6 and 99.7 is more to be expected. And that’s more than a day of downtime per year. If you have a website for your company in the fields of engineering, finance, medicine or IT this might not feel great. First impressions last a life time and “The IT company that can’t keep their own web page up” isn’t good PR.
Well you can set up a halfway decent backup to your website, ready to take over if the primary server goes down. I’ll be assuming that you use Cloudflare’s Load Balancer but other solutions will work too, I guess. What we’re interested in here is how to make the backup properly synchronized with the version of the website that is publically accessible when things are running smoothly. Now we have to get kind of “engineeringy” and specify what we can and can not fit into this box.
First off, what will be presented below will mostly be suitable for information websites that don’t see updates every few minutes like an ecommerce site. Even a website that sees a lot of comments to articles will seem kind of wonky after failover when set up as below.
It’s also important for the people running the site to keep track of failovers happening. This is trivial since Cloudflare will send out emails about the primary and the backup going up or down, but that doesn’t mean people can’t screw it up. Like having the emails go to one person and then that person goes on vacation and well, you can see where this is going.
So the idea here is that we simply use rsync and MySQL command line tools to sync the primary web site to the backup every couple of hours. The crontab entry running on my backup server looks like this:
Here is an important detail : this is not just done when the backup hasn’t received any writes. If this was a live site that failed over and happy-go-lucky editors made changes to the backup web site thinking that it’s the primary then they would have at most four hours before their dreams were crushed.
You could try to make this contingent on there not having been any successful POSTs made recently and send out an email if it has. Like “Can’t update backup website. It has recent changes that would be lost!”
But it’s more robust to just keep track of failovers happening as notified by Cloudflare. High availability always comes at some cost, whether it be features, money, usability, overhead etc. Here the cost is mostly overhead in the form of people needing to keep an eye out for emails like this:
Fri, 04 Dec 2020 19:28:59 UTC | DOWN | Origin ker.oderland.com from Pool Main_server | Response code mismatch error
Now, could you use this same setup for an ecommerce site? Yes… But that’s pushing your luck. I would strongly recommend against it. There are assumptions made here about the database dumps being small, the updates spaced out a lot over time and so on that don’t fit ecommerce. I have a better example of how one can set that up but the complexity goes up a bit.
Extra security
To limit the backup server to accepting HTTP/HTTPS requests from Cloudflare servers and only accept SSH requests from your own IP:
iptables -A INPUT -i eth0 -p tcp -s YOURIPADDRESS --dport 22 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp --sport 22 -m state --state ESTABLISHED -j ACCEPT
iptables -A OUTPUT -o eth0 -p tcp --sport 22 -m state --state ESTABLISHED -j ACCEPT
iptables -A OUTPUT -o eth0 -p tcp --dport 22 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 173.245.48.0/20 --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 103.21.244.0/22 --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 103.22.200.0/22 --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 103.31.4.0/22 --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 141.101.64.0/18 --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 108.162.192.0/18 --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 190.93.240.0/20 --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 188.114.96.0/20 --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 197.234.240.0/22 --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 198.41.128.0/17 --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 162.158.0.0/15 --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 104.16.0.0/12 --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 172.64.0.0/13 --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 131.0.72.0/22 --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 10.0.0.2/32 --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 173.245.48.0/20 --dport 443 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 103.21.244.0/22 --dport 443 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 103.22.200.0/22 --dport 443 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 103.31.4.0/22 --dport 443 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 141.101.64.0/18 --dport 443 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 108.162.192.0/18 --dport 443 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 190.93.240.0/20 --dport 443 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 188.114.96.0/20 --dport 443 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 197.234.240.0/22 --dport 443 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 198.41.128.0/17 --dport 443 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 162.158.0.0/15 --dport 443 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 104.16.0.0/12 --dport 443 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 172.64.0.0/13 --dport 443 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 131.0.72.0/22 --dport 443 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp -s 10.0.0.2/32 --dport 443 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A OUTPUT -o eth0 -p tcp --sport 80 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A OUTPUT -o eth0 -p tcp --sport 443 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A OUTPUT -o eth0 -p tcp --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A OUTPUT -o eth0 -p tcp --dport 443 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p udp --sport 53 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp --sport 80 -m state --state ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp --sport 443 -m state --state ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p udp --dport 51820 -j ACCEPT
iptables -A OUTPUT -o eth0 -p udp --dport 53 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A OUTPUT -o eth0 -p udp --sport 51820 -j ACCEPT
iptables -P INPUT DROP
iptables -P FORWARD DROP
iptables -P OUTPUT DROP
Allows outgoing DNS, HTTP and HTTPS connections so you can update the server as per usual. If you want to disable these rules for whatever reason, run this:
iptables -F only flushes the explicit rules, it doesn’t change the default action for INPUT, OUTPUT and FORWARD so they remain “DROP” and you can’t access the server remotely any more. Learnt that the hard way!
Cloudflare has a Load Balancer service that you can also use a failover service. The base version costs $5 a month(as of 2020-12-05) and allows for two origins which goes a long way. Configure your domain to use their name servers and set your domain up in the client area to be proxied through Cloudflare before proceeding with the load balancer setup.
Some nomenclature:
Origin => Server Pool => Collection of Origins Fallback pool => Pool of last resort(not relevant when there are only two pools)
To get failover functionality only we create one pool for the primary server and another pool for the backup. This is a working setup using the server ker.oderland.com as the primary and a VPS external.svealiden.se as the backup:
Let’s look at how each origin is configured. First the primary:
Note how we have one Origin only and that it is referred to not by the website name deref.se(which points to Cloudflare remember?) but the server name. Don’t worry about virtual hosting. Cloudflare understands that it needs to preserve the Host-header when forwarding traffic to origin servers.
Basically it’s the same for the backup just different information for the Origin. Same Health Check Region, same Monitor and the same Notification settings.
Health Check Region should be pretty self-explanatory but Monitoring isn’t. I have a single Monitor that checks the start page of my web page for status code 200 and the string “Digging”:
Note the advanced settings where the check in Response Body and the Host-header specification at the bottom are non-standard. This is a WordPress page so the Host-header needs to be correct even for my VPS that doesn’t rely on virtual hosting. Checking more frequently than every 60 seconds costs more money but it already seems reasonable to me. The monitor should be assigned to both origins as we saw earlier.
If you want to avoid even a few minutes of downtime when planned maintenance is scheduled for your primary origin you can just promote the backup manually by changing the order of the pools:
There are a number of gotchas to consider for any primary/secondary failover setup and I’ll go through some alternatives in separate posts(see Basic “information website” failover and “the other one I’m going to write maybe”) but here are some specific to Cloudflare’s UI:
Do not just have one pool in the “Origin Pools” category even if the backup pool is chosen as your fallback. That’s not how it works. It’s the contents of the Origin Pools section that determines which Pools are used and what priority they have. It makes no sense to not include the Fallback Pool among the Origin Pools-section.
The fallback pool will always show “No health”. Don’t worry about it. If any pool in the Origins Pool section shows “No health”, then you have a problem. But all you need to do is to add a monitor to that pool.
Don’t add multiple origins to a single pool if your don’t actually want to spread out traffic across multiple servers. And you probably don’t because that’s a multi-master setup and that means huge head aches.
SSL
What to do about SSL? We can’t use Let’s Encrypt on the backup and it might even be tricky on the primary. Not to worry, just install Cloudflare’s self-signed certificates: https://support.cloudflare.com/hc/en-us/articles/115000479507
They have 15 year validity so while it’s slightly awkward to install you don’t have to do it very often. Cloudflare of course shows a valid certificate for the ordinary visitor who connects to the Cloudflare proxies(click on the certificate for this page to see for yourself) but the communication between Cloudflare and the origin servers uses these 15-year self-signed certificates.
Drawbacks
So is Cloudflare Load Balancer a good failover solution? Well… I’m not 100% positive to it. Cloudflare have had global outages lasting from 30 minutes to an hour. Not every year but often enough for me to be skeptical of trusting them with the role of being a high availability load balancer.
I would have been okey with using external name servers made to point to Cloudflare proxies and use short TTLs. Then – if Cloudflare goes down – I can change the pointers and then we’re talking (my response time) + (TTL) downtime. But that complicates matters a bit for issuing SSL certificates so it’s not ideal.
Note that the two servers used in this setup are hosted by the same company. That’s fine for a test setup but it’s a bad idea in a live environment. Don’t trust Amazon Availability Zones to be independent either. Have your primary and your backup with different companies using different infrastructure!
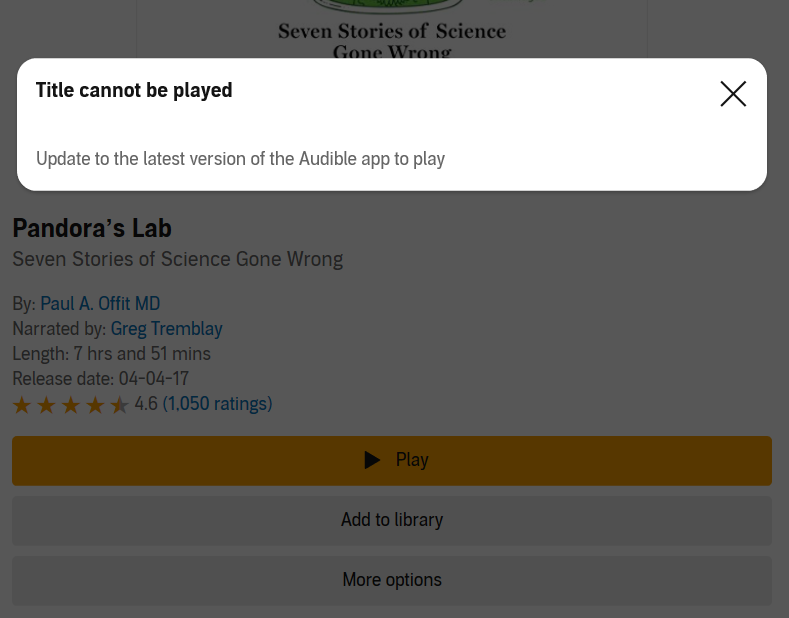
At approximately 18:40 I thought I might acquire some kind of audiobook… thing. Maybe Audible.com? They have some subscription thing, right? At 19:35 I gave up trying to access Pandora’s Lab, part of the content included in my trial month, to have a nap.
Re-envigorated by my nap I was able to listen to the book I acquired using my monthly credit. Success! Does that mean I can access that Pandora’s Lab thing as well? Does it bollocks. I can buy it when I visit audible.com using Google Chrome – the same browser which let me listen to the aforementioned book, so I’m logged in it would seem – but listen to it as included content? Nope.
The Windows 10 App does show it as included, which seems like a step in the right direction:
3
This doesn’t work quite the entire way:
After reading up on this it turns out that their Windows 10 App doesn’t yet have support for Audible Plus content. Wow! So that’s where the Windows platform is at right now, getting the cold shoulder from content providers?
Well, okey then. I guess they only really support mobile apps? Nope, not Android at least. It also just let’s me buy that book.
So I’m coming away from this somewhat unclear on the benefits of Audible Plus. I’m not entirely confident in buying books from them either given this evening’s little expedition. Maybe I need to buy an iPhone, a Kindle or Alexa to have solid access to their content? I’ll admit that a Kindle would probably be okey but I wouldn’t be able to show my face at work carrying an iPhone. Techies don’t use iPhones! I’m not even sure I would be able to look myself in the mirror if I used an iPhone. Yet it would be better than an Alexa which in turn is only slightly better than being kidnapped by an Eastern European organ-harvesting syndicate.
What is it with providers of audio content? Because this is largely my experience with iTunes as well. I’ve set up a multi-master MariaDB cluster in the time it takes me to jump through their hoops of updates of the iTunes executable, my account details, managing which units can access me content et cetera. I haven’t played any of the content on my iTunes account for at least two years at this point.
Netflix? My mom watches lots of their content on her television and she’s not exactly a grade A hacker. Sure I had to set it up for her but it’s largely painless from that point. So for some reason video content is easy to access from many devices while audio content is provided by organisations that compete with one another in who can most closely resemble a Soviet era bureaucracy. “Here is your car. Please wait 8-10 years for your petrol purchasing-license to clear.”
So I updated my Proxmox servers a few weeks ago. One worked fine but for two of them Ceph couldn’t start OSD:s for two drives. The processes segfaulted as it read through each disk and started over. I had to blank the drives and resync them. Well that’s not kosher! I was going to update Proxmox anyway so maybe it will be better with Ceph Nautilus which comes with Proxmox 6.2. Does it bollocks!
I upgrade one server at a time. One server is blanked and installed with Proxmox 6.2 and a new Ceph cluster is created with replica size 1. I then rsync data over from the old cluster. I had run this setup for 48 hours when a sudden reboot of the server left Ceph unable to read from two hard drives containing the CephFS. This time there was at least an error logged, not just a segfault:
Well, you get the idea. So that’s #¤§* it! It’s not that I can’t work around these issues and blank drives and bring them back into the cluster, but I have zero tolerance for buggy file systems and database engines. I run the old Luminous release for which there has been ample time to iron out kinks and OSD:s can’t start. I switch over to Nautilus: same but different.
I’ll run a toy Ceph-cluster in a couple of VM:s but for actual workloads? How about no? This means standard logical volumes for VM:s and btrfs for my 2TB of files. I’ll go back to my old btrfs script with the “send snapshot” functionality activated. I’ve run it without that send-snapshot thing for a while as a DB backup solution(a plan that turned out less than ideal which I should have predicted for such high IOPS applications).
Memo to self: if running Ceph in production, set up a staging cluster that can be upgraded and beaten about before rolling out the same release to the real cluster.
As we saw in part 1 of this series, MySQL is pretty robust in the face of hard resets as long as you use InnoDB as the underlying engine rather than MyISAM. Heck, InnoDB even held together with the cache-setting “Writeback (unsafe)” in Proxmox chosen for the underlying disk. But an ib_logfile getting corrupted or going missing somehow leaves us in a pickle. Some percentage of tables are likely to be impossible to export if that happens. So we better set things up so that we have something to fall back on if that happens.
Let’s start with my favorite, Btrfs snapshots. Some background:Ext4 is pretty much the default file system for Linux today and it’s pretty darned good. I remember back in the day when we only had Ext2 and it was a big deal when Ext3 introduced journals that made recovery from crashes much faster. Now we’re at Ext4. Btrfs on the other hand is a completely new file system heavily inspired by ZFS. It’s Copy-on-Write amongst other things which is good for snapshots. So Ext4 is tried and tested and Btrfs feature-rich.
Let’s switch from Ext4 to Btrfs for a MySQL-deployment. Note that I’m completely wiping the data stored in MySQL here! This is a test-rig.
I’ll make cron run a script that makes snapshots of the MySQL data directory every five minutes. It could be done in a simpler way but my script cleans up old snapshots automatically based on an assigned lifespan which is handy. This is what we end up with after slightly less than an hour of running the standard workload-script and also taking snapshots every five minutes:
root@mysqlrecov1:/var/lib/mysql# ls -lh Snapshots/data
total 0
drwxr-xr-x 1 mysql mysql 388 Mar 21 22:54 data@auto-2020-03-21-2340_12h
drwxr-xr-x 1 mysql mysql 388 Mar 21 22:54 data@auto-2020-03-21-2345_12h
drwxr-xr-x 1 mysql mysql 388 Mar 21 22:54 data@auto-2020-03-21-2350_12h
drwxr-xr-x 1 mysql mysql 388 Mar 21 22:54 data@auto-2020-03-21-2355_12h
drwxr-xr-x 1 mysql mysql 388 Mar 21 22:54 data@auto-2020-03-22-0000_12h
drwxr-xr-x 1 mysql mysql 388 Mar 21 22:54 data@auto-2020-03-22-0005_12h
drwxr-xr-x 1 mysql mysql 388 Mar 21 22:54 data@auto-2020-03-22-0010_12h
drwxr-xr-x 1 mysql mysql 388 Mar 21 22:54 data@auto-2020-03-22-0015_12h
drwxr-xr-x 1 mysql mysql 388 Mar 21 22:54 data@auto-2020-03-22-0020_12h
drwxr-xr-x 1 mysql mysql 388 Mar 21 22:54 data@auto-2020-03-22-0025_12h
So let’s say something bad happened after the last snapshot was taken and we want to get data out of it. Can we just start a MySQL-instance with the snapshot directory as the datadir? No.
I make all my snapshots read-only because they’re meant to be backups. The more immutable they are the better. MySQL can’t run against a read only copy. But all we need to do is to make a writable copy of the read-only snapshot we’re interested in.
I guess I could have run mysqlcheck to demonstrate that things were okey but they were just fine. We could have taken whichever of these snapshots we wanted and gone back to that point in time. As much as I like this setup I do recognize some weaknesses.
First, backups are necessarily part of the same filesystem as the original. So file system corruption can leave us completely boned. There is a mechanism for sending snapshots from one Btrfs file system to another – even on another server – which can remedy that situation to some extent. But Btrfs snapshots are not great to write to tape however you twist and turn things.
Second, we’re not actually saving snapshots that MySQL gives guarantees for. MySQL has to do a sort of crash recovery process when starting up these snapshots because they look just like what you would get if the server had crashed unexpectedly and left lots of databases open.
One way to remedy this is to use a backuptool like xtrabackup. There’s a version for MariaDB called mariabackup that’s basically the same. I’ll use xtrabackup in this case. We’ll make three snapshots, consisting of one full backup and two incremental backups. Then we’ll do a restore by applying each incremental backup to the full backup and then moving the result into the place MySQL expects data to be.
This has the benefit of saving cleaner snapshots and you get them in distinct files that are easier to save to tape or backup to some external storage provider.
Now let’s try something a bit more robust, replication! I have that set up for my own databases but with an older method of keeping the various copies in sync. I’d like to try out GTID. I wonder if it’s enabled by default on this version of MySQL?
mysql> SHOW GLOBAL VARIABLES LIKE '%gtid%';
+----------------------------------+-------+
| Variable_name | Value |
+----------------------------------+-------+
| binlog_gtid_simple_recovery | ON |
| enforce_gtid_consistency | OFF |
| gtid_executed | |
| gtid_executed_compression_period | 1000 |
| gtid_mode | OFF |
| gtid_owned | |
| gtid_purged | |
| session_track_gtids | OFF |
+----------------------------------+-------+
8 rows in set (0.00 sec)
Nope. Okey, I wonder if I can add it after the fact? Well activating the feature after the fact can obviously be done, but will it work? Will slaves only see the modifications that happened after GTID was activated? We can test it. Let’s enable GTID and create a replication user.
Now for a tricky move. It’s not strictly necessary since we know writes aren’t going on but for the sake of doing things by the book, we flush all table and lock them in one terminal window and then dump all databases in another. As long as the “FLUSH TABLES WITH READ LOCK;”-session is open in MySQL the lock is held and the dump is consistent.
Then we copy the dump to mysqlrecov2 where we import it into a blank setup. Then we configure that server for replication with it’s own server-id. Then we set up the replication and run a test to see if it works. We should be able to run our testscript and find that the maximum id in the Purchase-table(for instance) is the same for mysqlrecov1 and mysqlrecov2.
That seems to work fine. Let’s level this up one more notch. I’ll schedule snapshots to be made of the /var/lib/mysql/data directory every five minutes just like on mysqlrecov1 before. This will be a variant of what we did before. So the testscript is running against mysqlrecov1 for a while and mysqlrecov2 is replicating all the changes in real time. Snapshots are being stored in /var/lib/mysql/Snapshots/data/ on mysqlrecov2. There are actually good reasons for not storing snapshots on mysqlrecov1 which we can get to later. For now, let’s just note that the relay-log from mysqlrecov1 is ticking up nicely on mysqlrecov2:
Now let’s simulate a bonehead mistake. Something like deleting all customers in the database with an id below 5000? That should leave people quite sad. As we saw before we can restore from a Btrfs snapshot but we can lose up to 5 minutes of transactions. In fact, if we don’t recognize our bonehead mistake immediately and take MySQL down on mysqlrecov1 we could rack up even more transactions that will be lost when we go back to our earlier state.
Replication worked just as advertised. Within milliseconds of me deleting a bunch of customers at random on mysqlrecov1, mysqlrecov2 followed suit. As SHOW SLAVE STATUS illustrated at the end, I kept the testscript running for a while longer so more and more gtid_sets were stored on mysqlrecov2 full of legitimate transactions.
The test script started printing a lot more error messages after some random customers got deleted but kept running anyway. So what are we going to do now? Well restoring the last Btrfs snapshot from before the deletion is a good start. We’ll turn off mysqlrecov1 and set mysqlrecov2 so that it can only be reached from the server itself, to keep people from tinkering with the data while we’re working on it.
Seems I chose the right snapshot. We have customer with ids below 5000. Now let’s check in the relay-log from the data_borked directory. We don’t want MySQL to use that directory any more because the data in ib_logdata-files and the sysbench-directory reflects the state where thousands of customers are missing. But the relay-log file is still very valuable. If we run mysqlbinlog –verbose /var/lib/mysql/data_borked/mysqlrecov1-relay-log.00005 we see all the changes made to the database since replication began. This data gets rotated out eventually but here neither time nor space-constraints led any of the changes to be lost before the “mistake” was discovered. We only really need the changes made from the point the latest good snapshot is from to make this work though.
So how does the binlog look?
SET @@SESSION.GTID_NEXT= 'b6efad3f-6c71-11ea-9af3-eaa32fa23308:1586'/*!*/;
# at 472
#200328 22:41:23 server id 1 end_log_pos 337 CRC32 0x633797ec Query thread_id=3 exec_time=0 error_code=0
SET TIMESTAMP=1585435283/*!*/;
SET @@session.pseudo_thread_id=3/*!*/;
SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/;
SET @@session.sql_mode=1436549152/*!*/;
SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;
BEGIN
/*!*/;
# at 550
#200328 22:41:23 server id 1 end_log_pos 399 CRC32 0x2b1e9803 Table_map: `sysbench`.`Customer` mapped to number 108
# at 612
#200328 22:41:23 server id 1 end_log_pos 480 CRC32 0xc9c162b2 Write_rows: table id 108 flags: STMT_END_F
BINLOG '
k9J/XhMBAAAAPgAAAI8BAAAAAGwAAAAAAAMACHN5c2JlbmNoAAhDdXN0b21lcgAEAw8DDwT/AP8A
CAOYHis=
k9J/Xh4BAAAAUQAAAOABAAAAAGwAAAAAAAEAAgAE//CF4AMAFGNiZnVkbmJmbWxtd2h1YWptbHht
AAAAAA94c3dqZnh1ZmhwZ3NpbWGyYsHJ
'/*!*/;
### INSERT INTO `sysbench`.`Customer`
### SET
### @1=254085
### @2='cbfudnbfmlmwhuajmlxm'
### @3=0
### @4='xswjfxufhpgsima'
# at 693
#200328 22:41:23 server id 1 end_log_pos 511 CRC32 0x0a071603 Xid = 46
COMMIT/*!*/;
# at 724
#200328 22:41:24 server id 1 end_log_pos 576 CRC32 0x05680f0e GTID last_committed=1 sequence_number=2 rbr_only=yes
/*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/;
SET @@SESSION.GTID_NEXT= 'b6efad3f-6c71-11ea-9af3-eaa32fa23308:1587'/*!*/;
# at 789
#200328 22:41:24 server id 1 end_log_pos 654 CRC32 0x79a206c9 Query thread_id=12 exec_time=0 error_code=0
SET TIMESTAMP=1585435284/*!*/;
BEGIN
/*!*/;
# at 867
#200328 22:41:24 server id 1 end_log_pos 716 CRC32 0xa2bb0bb0 Table_map: `sysbench`.`Customer` mapped to number 108
# at 929
#200328 22:41:24 server id 1 end_log_pos 797 CRC32 0xf9f2cb8b Write_rows: table id 108 flags: STMT_END_F
<...>
Okey, slightly obscure. Can we find our DELETE FROM Customer WHERE id < 5000? No. We only find thousands of these:
SET @@SESSION.GTID_NEXT= ‘b6efad3f-6c71-11ea-9af3-eaa32fa23308:26067’/*!*/; # at 14852899 #200328 23:02:33 server id 1 end_log_pos 14852762 CRC32 0xb87efd39 Query thread_id=4 exec_time=0 error_code=0 SET TIMESTAMP=1585436553/*!*/; BEGIN /*!*/; # at 14852975 #200328 23:02:33 server id 1 end_log_pos 14852825 CRC32 0x6a5f0dd7 Table_map: `sysbench`.`Purchase_list` mapped to number 110 # at 14853038 #200328 23:02:33 server id 1 end_log_pos 14852894 CRC32 0x53b1b9b6 Delete_rows: table id 110 flags: STMT_END_F
BINLOG ‘ idd/XhMBAAAAPwAAANmi4gAAAG4AAAAAAAEACHN5c2JlbmNoAA1QdXJjaGFzZV9saXN0AAQDAwMD AADXDV9q idd/XiABAAAARQAAAB6j4gAAAG4AAAAAAAEAAgAE//Dw5AEAlMQAAKJQAAAEAAAA8PLkAQCUxAAA n3MAAAYAAAC2ubFT ‘/*!*/; ### DELETE FROM `sysbench`.`Purchase_list` ### WHERE ### @1=124144 ### @2=50324 ### @3=20642 ### @4=4 ### DELETE FROM `sysbench`.`Purchase_list`
So what is the latest transaction before the first of these thousands of DELETE-operations? Well, I know approximately what time we’re interested in. Then we can just look for DELETE FROM `sysbench`.`Customer`-statements.
So this probably contains the data we’re interested in:
### @2='trirwseikshnmaeuqgzr'
### @3=3522
### @4='peahbpigywdapfo'
# at 14574860
#200328 23:01:06 server id 1 end_log_pos 14574678 CRC32 0xab48065f Xid = 758546
COMMIT/*!*/;
# at 14574891
#200328 23:01:07 server id 1 end_log_pos 14574743 CRC32 0x18eab10c GTID last_committed=24333 sequence_number=24334 rbr_only=yes
/*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/;
SET @@SESSION.GTID_NEXT= 'b6efad3f-6c71-11ea-9af3-eaa32fa23308:25919'/*!*/;
# at 14574956
#200328 23:01:07 server id 1 end_log_pos 14574821 CRC32 0xe10dc87f Query thread_id=16 exec_time=0 error_code=0
SET TIMESTAMP=1585436467/*!*/;
SET @@session.foreign_key_checks=0/*!*/;
BEGIN
/*!*/;
# at 14575034
#200328 23:01:07 server id 1 end_log_pos 14574883 CRC32 0x6e71054b Table_map: `sysbench`.`Customer` mapped to number 108
# at 14575096
#200328 23:01:07 server id 1 end_log_pos 14583060 CRC32 0x65200e62 Delete_rows: table id 108
All right, what is the last state found in the last good snapshot? SHOW SLAVE STATUS says that Read_Master_Log_Pos is 14507560. That’s a reasonable number given that we just found the marker “end_log_pos 14574678” just above where all the bad deletes started. It’s important to know if 14507560 is an end_log_pos or a start position. Searching through the binlog-output reveals that it is an end_pos:
### @3=1682
### @4='vlntfrggrwhykju'
# at 14507742
#200328 23:00:00 server id 1 end_log_pos 14507560 CRC32 0x333e7f0b Xid = 753352
COMMIT/*!*/;
# at 14507773
So we will want to replay from the start position 14507773 that comes directly after the number we found in SHOW SLAVE STATUS. And the final position to include is 14574678.
Okey, so we were able to apply parts of the binlog without running into “DUPLICATE KEY” errors or losing lots of customer data. Shall we try to apply the transactions after the erroneous deletes? Should be as simple as replaying the binlog from position 14766269 to the end.
Seems okey. According the output from the testscript one of the last transactions was a purchase registered to customer 8786 with a cost of 351.
root@mysqlrecov2:/var/lib/mysql/data_borked# mysql
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 9
Server version: 5.7.29-0ubuntu0.18.04.1-log (Ubuntu)
Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> USE sysbench;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> SELECT * FROM Purchase WHERE customer_id = 8786;
+-------+-------------+------+--------+
| id | customer_id | cost | weight |
+-------+-------------+------+--------+
| 58333 | 8786 | 351 | 745 |
+-------+-------------+------+--------+
1 row in set (0.00 sec)
mysql>
If this had been a live system I would have been okey with bringing this online again. Since this was a small database a mysqldump and restore back on the master would work. For a bigger system maybe promoting the fixed slave is better and making the previous master into the new slave. Anyway, the testscript agrees that the data is correct:
cjp@kdemain:~/sysbench$ bin/python3.7 ownsysbench.py --hosts 192.168.1.155 --check true
192.168.1.155
Connection to 192.168.1.155: <mysql.connector.connection.MySQLConnection object at 0x7f05b26329d0> by X
self.conn.in_transaction: False
Checking correctness
Numbers check out on a high level. Checking each customer.
cjp@kdemain:~/sysbench$
It’s a few years old by now but I don’t doubt that Btrfs is still terrible for your database storage if you want to maximize throughput. My real world databases sees maybe 10-20 queries per seconds. My backup software can peak at hundreds per second(I blame the Java ORM-layer, not the me the programmer) for short bursts. Btrfs doesn’t slow that down noticeably. If someone asks me to setup a system that sees sustained loads of 5000 transactions per second I’ll ditch Btrfs in an instant on the master and only use it on the slaves. Because slaves typically don’t do much work. They just stream the results that result from all the work done on the master.
Anyway, I think those are the building blocks for safeguarding MySQL databases. There are some additional tweaks like having one slave intentionally trail behind the master a certain number of minutes to make recovery from bonehead mistakes easier. There are also more synchronous solutions like Galera(I’ve used Percona’s XtraDB variant) to minimize the gap during which a write to a master might be lost because it hasn’t reached any slaves yet.
NOTE! These are mostly for my reference working on this post.
root@mysqlrecov2:~# mysqlbinlog /var/lib/mysql/data/mysqlrecov2-relay-bin.000002 | less
<jibberish>
Well that didn’t produce very readable information. This turned out to be better for viewing:
root@mysqlrecov2:~# mysqlbinlog --verbose /var/lib/mysql/data/mysqlrecov2-relay-bin.000002 | less
#200322 21:14:57 server id 1 end_log_pos 894 CRC32 0x8df90820 Query thread_id=9 exec_time=0 error_code=0
SET TIMESTAMP=1584911697/*!*/;
BEGIN
/*!*/;
# at 1107
#200322 21:14:57 server id 1 end_log_pos 956 CRC32 0x18b0e814 Table_map: `sysbench`.`Customer` mapped to number 116
# at 1169
#200322 21:14:57 server id 1 end_log_pos 1037 CRC32 0xa46a830a Write_rows: table id 116 flags: STMT_END_F
BINLOG '
UdV3XhMBAAAAPgAAALwDAAAAAHQAAAAAAAMACHN5c2JlbmNoAAhDdXN0b21lcgAEAw8DDwT/AP8A
CBTosBg=
UdV3Xh4BAAAAUQAAAA0EAAAAAHQAAAAAAAEAAgAE//B64AMAFHZ5YmdveWd0bWhwdHd6eGd3bWZy
AAAAAA9maWhmeW9sYndha21wYm0Kg2qk
'/*!*/;
### INSERT INTO `sysbench`.`Customer`
### SET
### @1=254074
### @2='vybgoygtmhptwzxgwmfr'
### @3=0
### @4='fihfyolbwakmpbm'
# at 1250
How to find current log position? Or some way of figuring which position in the bin log a specific file system snapshot matches. This?
mysql> SHOW MASTER STATUS;
+------------------+----------+--------------+------------------+---------------------------------------------------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+---------------------------------------------------------------------------------------+
| mysql-bin.000001 | 786 | | | 1176771d-6c7e-11ea-a68b-1a389890e7c2:1-3,
b6efad3f-6c71-11ea-9af3-eaa32fa23308:1-2769 |
+------------------+----------+--------------+------------------+---------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
But it says this at the end of mysqlrecov2-relay-bin.000002…
#200322 21:23:07 server id 1 end_log_pos 1739591 CRC32 0xa5d8a74e Xid = 82080
So what’s all this about mysqlrecov2-relay-bin.000001? And position 786 is suspect. Well, I guess File and Position are separate from GTID. So I shouldn’t be looking at File and Position because I use GTID? But I can’t very well make out anything sequential from a GTID. They’re UUIDs.
Okey, okey. Now I get it. So we have a GTID for the data synced from the master, that’s _b6efad3f-6c71-11ea-9af3-eaa32fa23308:1-2769_ and we can find matching information in mysqlrecov2-relay-bin.000002. Indeed the last segment in that file reads:
last_committed=2766 sequence_number=2769
So that checks out. The other GTID refers to the local machine and so we find that information in /var/log/mysql/mysql-bin.000001 . Notice that this is not a binlog we replicated in from the master. So nothing relay about this file. This GTID set only contains the part where I added the sysbench user so that I could run the script against the slave to make sure it was consistent. I’m not replicating the mysql-database since I don’t know if that’s safe.
All right, let’s break the database and try to recover using a combination of snapshots and binlog.
mysql> SET FOREIGN_KEY_CHECKS=0;
Query OK, 0 rows affected (0.00 sec)
mysql> DROP FROM Customer WHERE id < 5000;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'FROM Customer WHERE id < 5000' at l
ine 1
mysql> DELETE FROM Customer WHERE id < 5000;
Query OK, 4285 rows affected (4.87 sec)
Let’s see what the sanity check says:
192.168.1.154
Connection to 192.168.1.154: <mysql.connector.connection.MySQLConnection object at 0x7fa1487cf8d0> by X
self.conn.in_transaction: False
Checking correctness
Sums of credit(753818484), costs(-20278036 and deposits(787452535) don't check out. Something is wrong.
Credit exists for 1 but no such customer exists.
Credit exists for 2 but no such customer exists.
Credit exists for 4 but no such customer exists.
Credit exists for 5 but no such customer exists.
Credit exists for 6 but no such customer exists.
Credit exists for 9 but no such customer exists.
Credit exists for 10 but no such customer exists.
Credit exists for 11 but no such customer exists.
Credit exists for 14 but no such customer exists.
Credit exists for 15 but no such customer exists.
<...>
And so on for thousands of lines. Found the last bit before the big delete block:
### INSERT INTO `sysbench`.`Product`
### SET
### @1=57331
### @2='awcioutbwumewtopjnhx'
### @3=54
### @4=9
# at 15852327
#200323 21:54:32 server id 1 end_log_pos 15852145 CRC32 0x4918e08a Xid = 731899
COMMIT/*!*/;
# at 15852358
#200323 21:54:27 server id 1 end_log_pos 15852210 CRC32 0x2b6858df GTID last_committed=32482 sequence_number=32483 rbr_only=yes
/*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/;
SET @@SESSION.GTID_NEXT= 'b6efad3f-6c71-11ea-9af3-eaa32fa23308:32483'/*!*/;
# at 15852423
#200323 21:54:27 server id 1 end_log_pos 15852288 CRC32 0xe0637123 Query thread_id=93 exec_time=0 error_code=0
SET TIMESTAMP=1585000467/*!*/;
SET @@session.foreign_key_checks=0/*!*/;
BEGIN
/*!*/;
# at 15852501
So the sequence number is 32483. So let’s try to start up the latest snapshot and see what the last sequence number was then.
mysql> SHOW MASTER STATUS;
+------------------+----------+--------------+------------------+----------------------------------------------------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+----------------------------------------------------------------------------------------+
| mysql-bin.000003 | 194 | | | 1176771d-6c7e-11ea-a68b-1a389890e7c2:1-3,
b6efad3f-6c71-11ea-9af3-eaa32fa23308:1-19756 |
+------------------+----------+--------------+------------------+----------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
All right, between 19756 and 32483 is the koscher sequence to replay:
root@mysqlrecov2:/var/lib/mysql# mysqlbinlog --skip-gtids --start-position=19756 --stop-position=32483 /var/lib/mysql/data/mysqlrecov2-relay-bin.000002 > replay.sql ERROR: Error in Log_event::read_log_event(): 'read error', data_len: 2054581866, event_type: 103 ERROR: Could not read entry at offset 19756: Error in log format or read error.
Huh? Oh for the love of… I have to use log_pos instead of sequence number? All right, so 32483 has end_log_pos 15852288 and 19756 has an “# at 10105794:
# at 10105794
#200323 21:50:01 server id 1 end_log_pos 10105646 CRC32 0x6ab793c0 GTID last_committed=19751 sequence_number=19756 rbr_only=yes
/*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/;
SET @@SESSION.GTID_NEXT= 'b6efad3f-6c71-11ea-9af3-eaa32fa23308:19756'/*!*/;
root@mysqlrecov2:/var/lib/mysql# mysql -S /tmp/mysqld2.sock < replay.sql
ERROR 1062 (23000) at line 35: Duplicate entry '54389' for key 'PRIMARY'
Okey, must have brought with us too many. Let’s see if I can find the next position:
root@mysqlrecov2:/var/lib/mysql# less replay.sql
root@mysqlrecov2:/var/lib/mysql# mysqlbinlog --verbose /var/lib/mysql/data/mysqlrecov2-relay-bin.000002 | less
root@mysqlrecov2:/var/lib/mysql# mysqlbinlog --skip-gtids --start-position=10106096 --stop-position=15852288 /var/lib/mysql/data/mysqlrecov2-relay-bin.000002 > replay2.sql
root@mysqlrecov2:/var/lib/mysql# mysql -S /tmp/mysqld2.sock < replay2.sql
Success! Maybe… Let’s try the sanity check:
cjp@kdemain:~/sysbench$ bin/python3.7 ownsysbench.py --hosts 192.168.1.155 --check true
192.168.1.155
Connection to 192.168.1.155: <mysql.connector.connection.MySQLConnection object at 0x7fb052407810> by X
self.conn.in_transaction: False
Checking correctness
Numbers check out on a high level. Checking each customer.
cjp@kdemain:~/sysbench$
Aw, yeah! So let’s dump out what we got here as valid snapshot:
root@mysqlrecov2:/var/lib/mysql# mysqld --daemonize --log-error-verbosity=3 --pid-file=/tmp/mysqld2.pid --socket=/tmp/mysqld2.sock --datadir=/var/lib/mysql/backup --port=3306
root@mysqlrecov2:/var/lib/mysql# mysqldump sysbench > after_bin1.sql
mysqldump: Got error: 2002: Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (2) when trying to connect
root@mysqlrecov2:/var/lib/mysql# mysqldump -S /tmp/mysqld2.sock sysbench > after_bin1.sql
Warning: A partial dump from a server that has GTIDs will by default include the GTIDs of all transactions, even those that changed suppressed parts of the database. If you don't want to res
tore GTIDs, pass --set-gtid-purged=OFF. To make a complete dump, pass --all-databases --triggers --routines --events.
root@mysqlrecov2:/var/lib/mysql# mysqldump --set-gtid-purged=OFF -S /tmp/mysqld2.sock sysbench > after_bin1_no_gtid.sql
Now let’s see if we can apply the events that followed after the “unfortunate” deletion of customers.
# at 16050579
#200323 21:54:32 server id 1 end_log_pos 16050431 CRC32 0xd46e91ef GTID last_committed=32482 sequence_number=32484 rbr_only=yes
/*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/;
SET @@SESSION.GTID_NEXT= 'b6efad3f-6c71-11ea-9af3-eaa32fa23308:32484'/*!*/;
# at 16050644
#200323 21:54:32 server id 1 end_log_pos 16050509 CRC32 0x6f245997 Query thread_id=66 exec_time=0 error_code=0
SET TIMESTAMP=1585000472/*!*/;
SET @@session.foreign_key_checks=1/*!*/;
Okey, so we only need start-position this time since we want everything from the end of the DELETE block:
cjp@kdemain:~/sysbench$ bin/python3.7 ownsysbench.py --hosts 192.168.1.155 --check true
192.168.1.155
Connection to 192.168.1.155: <mysql.connector.connection.MySQLConnection object at 0x7fb1bd586710> by X
self.conn.in_transaction: False
Checking correctness
Numbers check out on a high level. Checking each customer.
cjp@kdemain:~/sysbench$
The last legit operations(after I did the big “accidental” delete but just before I brought down the database master to contain the damage) were:
Purchase: Deducted 958 from customer 218820 landing at 1442
Deleted (83708,)
Credit id 270922: Added 6224 to 261395
Deleted (98105,)
Credit id 270952: Added 7045 to 261281
Purchase: Deducted 630 from customer 91130 landing at 2144
So is that last purchase now in the restored copy?
mysql> SELECT * FROM Purchase WHERE customer_id = 91130; +-------+-------------+------+--------+ | id | customer_id | cost | weight | +-------+-------------+------+--------+ | 55193 | 91130 | 630 | 550 | +-------+-------------+------+--------+ 1 row in set (0.00 sec)
And do we have customers with an ID below 5000?
mysql> SELECT COUNT(*) FROM Customer WHERE id < 5000; +----------+ | COUNT(*) | +----------+ | 4285 | +----------+ 1 row in set (0.00 sec)
Indeed we do! So we have successfully cut out a particular disastrous sequence of operations, piecing together a coherent view of customers, purchases, credits etc. And it only took me an hour and a half. Probably not the response time considered ideal by a trader seeing 100 or so purchases per second.
Note that there’s no guarantee that this method will work out this well in practice. Indeed I may well have lost purchases by doing this but in the interest of un-screwing things it would probably have been the best way forward. So don’t view snapshots and binlogs as a license to clown around with a production database.
On a personal note: would it not be beneficial to have less brittle data structures than this? In a relational database we might have the state of Texas as a row in the table States and if it goes missing then every row representing customers from Texas will generate an error on read. Foreign key constraint error presumably. Maybe MongoDB is going too far in the other direction but DUPLICATE KEY and FOREIGN KEY CONSTRAINT errors make relational databases so sensitive. I guess this is a struggle each IT department has to have with their respective accounting departments.
Let’s crash some MySQL-databases, shall we? Well that’s harder than it seems. Especially if you’ve had to recover crashed databases on production servers. If they – set up to be very reliable – can crash during a network failure or hard reset, how come I can’t replicate the same when I tweak all settings to be at their most unreliable? Maybe the uptime of the server, the size of the database on disk, number of distinct databases and so on play a role? Well, let’s try to investigate MySQL crash recovery as best we can.
Hmm, maybe we should first establish some method of simulating a workload? Well, I have a script that simulates the sort of workload that you would see in high volume eCommerce. It makes full use of transactions to make multiple updates to multiple tables happen atomically(i.e. completely or not at all). Basically it pretends that there are customers that add credit to their account and then make purchases using that credit. Let’s try it out:
The script ownsysbench.py starts on process per IP or hostname provided and each runs 12 threads that each simulate the workload. As we saw in mytop, the number of queries per second varies between 700 and 100. This is on a dual core VM running on an Intel Atom server. So I’m kind of impressed. But in fairness I ran this on an ext4 filesystem with nobarrier on and relaxed commit rules(https://dev.mysql.com/doc/refman/5.7/en/innodb-parameters.html#sysvar_innodb_flush_log_at_trx_commit). Let’s try it again with standard barrier for ext4 and default commit rules. Oh, maybe I should turn off Cache(unsafe) for the disk in Proxmox? That probably gave this run a performance advantage. Okey, so no extra disk caching, default flush of transactions to disk and ext4 has its barrier again:
So 600 to 800 queries per second. That’s not so bad. It’s not like it’s a tiny database either:
Well, 90 MB is kind of tiny but 200 000 customers is on the big side. With a smaller database we get up to 1200 and 1300 queries per second. Now, the point here is actually just to get a feel for what kind of load we’re putting on the system when we tweak variables. Even with all safeties on we have several hundred queries per second, of which many are INSERT and UPDATE.
So one could be forgiven for thinking that rebooting the server would cause problems. Whenever you pull the plug there will probably be a couple of transactions running. Let’s try it with these safe settings. I’m using a slightly smaller database size but we can try the big one later on:
I have set MySQL to not start automatically, to make it easier for me to spot error states. But as you can see, MySQL starts up without issue. It’s only when we look in the error.log(it’s a general log, not really sure why they named it that) that we see that some recovery-work had to be done. But it was entirely automatic.
5 transaction(s) which must be rolled back or cleaned up in total 6 row operations to undo
2020-03-21T21:19:59.885968Z 0 [Note] InnoDB: Trx id counter is 373760
2020-03-21T21:19:59.885997Z 0 [Note] InnoDB: Starting an apply batch of log records to the database...
<...>
2020-03-21T21:20:00.715726Z 0 [Note] InnoDB: Rolling back trx with id 373313, 1 rows to undo
2020-03-21T21:20:00.715914Z 0 [Note] InnoDB: Removed temporary tablespace data file: "ibtmp1"
2020-03-21T21:20:00.715974Z 0 [Note] InnoDB: Creating shared tablespace for temporary tables
2020-03-21T21:20:00.716079Z 0 [Note] InnoDB: Setting file './ibtmp1' size to 12 MB. Physically writing the file full; Please wait ...
2020-03-21T21:20:00.724026Z 0 [Note] InnoDB: Rollback of trx with id 373313 completed
2020-03-21T21:20:00.724074Z 0 [Note] InnoDB: Rolling back trx with id 373312, 1 rows to undo
2020-03-21T21:20:00.731498Z 0 [Note] InnoDB: Rollback of trx with id 373312 completed
2020-03-21T21:20:00.731537Z 0 [Note] InnoDB: Rolling back trx with id 373309, 1 rows to undo
2020-03-21T21:20:00.734520Z 0 [Note] InnoDB: Rollback of trx with id 373309 completed
2020-03-21T21:20:00.734557Z 0 [Note] InnoDB: Rolling back trx with id 373286, 1 rows to undo
2020-03-21T21:20:00.737645Z 0 [Note] InnoDB: Rollback of trx with id 373286 completed
2020-03-21T21:20:00.737681Z 0 [Note] InnoDB: Rolling back trx with id 373213, 2 rows to undo
2020-03-21T21:20:00.890034Z 0 [Note] InnoDB: File './ibtmp1' size is now 12 MB.
2020-03-21T21:20:00.891339Z 0 [Note] InnoDB: 96 redo rollback segment(s) found. 96 redo rollback segment(s) are active.
2020-03-21T21:20:00.891411Z 0 [Note] InnoDB: 32 non-redo rollback segment(s) are active.
2020-03-21T21:20:00.892242Z 0 [Note] InnoDB: Waiting for purge to start
2020-03-21T21:20:00.892640Z 0 [Note] InnoDB: Rollback of trx with id 373213 completed
2020-03-21T21:20:00.890034Z 0 [Note] InnoDB: File './ibtmp1' size is now 12 MB.
2020-03-21T21:20:00.891339Z 0 [Note] InnoDB: 96 redo rollback segment(s) found. 96 redo rollback segment(s) are active.
2020-03-21T21:20:00.891411Z 0 [Note] InnoDB: 32 non-redo rollback segment(s) are active.
2020-03-21T21:20:00.892242Z 0 [Note] InnoDB: Waiting for purge to start
2020-03-21T21:20:00.892640Z 0 [Note] InnoDB: Rollback of trx with id 373213 completed
2020-03-21T21:20:00.892756Z 0 [Note] InnoDB: Rollback of non-prepared transactions completed
mysqlcheck gave the tables a clean bill of health and the internal consistency is correct according the benchmark software itself:
cjp@kdemain:~/sysbench$ bin/python3.7 ownsysbench.py --hosts 192.168.1.154 --check true
192.168.1.154
Connection to 192.168.1.154: <mysql.connector.connection.MySQLConnection object at 0x7fbbda456710> by X
self.conn.in_transaction: False
Checking correctness
Numbers check out on a high level. Checking each customer.
cjp@kdemain:~/sysbench$
So I’ve tried turning off ext4’s barrier(letting writes be done a bit more sloppy), flush of innodb logs on transaction commit(they are then done once a second instead) and even that caching-mode in Proxmox called “Writeback (unsafe)”. InnoDB hasn’t given me a single complaint… As mentioned earlier, I have seen InnoDB crash in the wild so it’s not completely safe but I at least can hit it with a shovel for a couple of days and fail to make a dent.
I was planning on provoking an error which could be solved by starting MySQL in InnoDB force recovery mode level 1 and demonstrate how that can fix things. This setting(https://dev.mysql.com/doc/refman/5.7/en/forcing-innodb-recovery.html) is something you hope not having to fiddle with but when InnoDB does crash in some way, innodb_force_recovery is the way forward. We would move on to something that requires recovery level 2 or 3. All the way up past level 4. Levels 4 and up typically involve some data loss and usually requires exporting and importing all the databases.
As noted above however, no go on generating these kinds of errors as intended. But if we can’t get one of those elusive errors that can be solved with innodb_force_recovery=3 then I know a way to generate errors that can be “solved” with innodb_force_recovery=6. So let me reset the database server while it is running again, with 200 000 customers and maximum danger settings on. Then we can do some damage ourselves and see what happens.
Okey, that actually didn’t go to plan… I was expecting to have to go to level 6 and for mysqldump to fail at some stage. Maybe I deleted the wrong ib_logfile? I have a snapshot of the whole mysql partition after the reset. I can try again. No, now not even level 6 worked. All right, let’s start over. I have – as previously mentioned – been hitting this setup with a shovel for a couple of days.
So I switched to Btrfs instead of Ext4, for no other reason than feeling like it. Now let’s try that intentional break again:
Again we only had to go to level 5 of innodb_force_recovery but importantly we got stuck when trying to dump a specific table from the database. In a real life situation it’s easy to imagine how losing the list of items for all purchases would be a bad thing. I’m pretty sure audits by the IRS go better when you can show what you sold and to whom.
So while this doesn’t show tremendously well how to deal with more subtle forms of InnoDB crashes you get the general idea. Notice how I created a Btrfs snapshot before starting to tinker with stuff. That can be a good idea if the option is available. Here I intentionally broke something but the process of fixing things could actually break things even more. And the most important take-away here is that not all corruptions are recoverable. Even if all the data in the sysbench-folder is correct a failure in one of the ib_logfiles can leave you with entire tables being unrecoverable. You got to have backups!
So what about MyISAM? Well it’s a lot easier to break MyISAM. In fact, since the benchmark tool is based on transactions – and MyISAM doesn’t support transactions – I only need to run it for a few seconds to get garbage data out. Let’s first dig ourselves out of the hole we dug for ourselves.
But MyISAM says this clearly on the box so we can’t very well complain. Need transactions? Don’t use MyISAM. Need crash tolerance? Don’t use MyISAM. Have large table? Don’t use MyISAM. It’s surprising how many MySQL-databases in the world don’t conflict with those constraints and merrily run MyISAM without issue. But let’s break a MyISAM setup just for kicks!
This run was done with maximum safe settings. Btrfs doesn’t have a nobarrier equivalent as far as I know. But Proxmox added no caching and MySQL’s settings were conservative. The errors that arose were recoverable but we can’t tell if the contents of the databas is consistent with the application because as we saw before, MyISAM can’t guarantee that even when there’s no one doing a hard reset every couple of minutes.
So that was a slightly disjointed tour of MySQL failure and recovery. The next installment will be about how to cover our backs. Step 1 is clearly to use InnoDB as the underlying engine and I guess step 2 is not deleting ib_logfiles. Snapshots, binlogs and replication will follow.
Pacemaker is a piece of software for running a cluster of computers. It uses corosync to provide cluster communication and membership management in most deployments I believe. The command line tool on Ubuntu Linux is pcs. pcs status tells your what the cluster is doing and which nodes are currently members. pcs cluster start node2 starts node2, even if the command is executed on another server in the cluster.
What makes Pacemaker a bit different from other cluster management systems is that it handles those awkward mutual exclusion scenarios quite well. You may have heard about Keepalived used to provide high availability and Kubernetes is a popular cluster platform today. But neither can safely handled resources that require mutual exclusion. It’s perfectly possible for a Kubernetes node running a MariaDB instance to freeze, at which point Kubernetes starts up the same instance on another server, only for the original to suddenly come alive again.
Pacemaker supports fencing which makes sure that something that had a unique resource can not run it again without approval from the cluster. This is typically done by killing the previous runtime(virtual machine, physical server or whatever it may be) and waiting for a response message that gives us the assurance the previous runtime isn’t going to do something unexpected.
For physical hardware IPMI is typically used to do fencing, cutting the power to all the parts of the computer that aren’t the IPMI-board itself. It is necessary for the IPMI-unit to continue operating because fencing requires both the kill action and some verification that the kill action worked. A common method is to let IPMI reset the power to the server and the verification is simply the server waking up and asking the cluster software if it can join again.
If implemented properly fencing should give complete assurance that two instances of a database server won’t be accepting writes concurrently, or instances of a file system writing to shared storage without being synchronized. But that means that if we lose contact with a server and its IPMI module, then the node can’t be fenced and we can’t safely bring up a new instance of whatever software failed along with the server. A human being can typically resolve the situation but that may take time.
Note that it is highly desirable to have clusters that do not rely on mutual exclusion. Ceph is a storage system with no need for fencing as it is quorum based(a majority of nodes have to agree on things, leaving some wonky node that freezes for a minute every now and then out in the cold) and each node has it’s own local storage(so none of that troublesome shared storage). Similarly Galera is an addition the MySQL-based databases that allow for multiple masters simultaneously thanks to a system of mutual certification of each proposed transaction so that no two changes to the contents of the database are ever in conflict.
Install
First we need to set things up corosync. I have three nodes as specified below and the file /etc/corosync/corosync.conf shown below needs to be the same on all three:
totem {
version: 2
secauth: off
cluster_name: sveaha
transport: udpu
}
nodelist {
node {
ring0_addr: pcmk1.svealiden.se
nodeid: 1
}
node {
ring0_addr: pcmk2.svealiden.se
nodeid: 2
}
node {
ring0_addr: pcmk3.svealiden.se
nodeid: 3
}
}
quorum {
provider: corosync_votequorum
}
logging {
to_syslog: yes
to_logfile: yes
logfile: /var/log/cluster/corosync.log
# Log to the system log daemon. When in doubt, set to yes.
}
Then we need to generate an authkey – which by default is expected to be in /etc/corosync/authkey. It’s sufficient to generate it using this command(you don’t need to cd into any specific directory, the command knows where to place the key):
corosync-keygen
To make sure the configuration is correct on all three nodes I just used scp threeway copy:
Jul 06 17:23:21.251 [2247] pcmk1 corosync notice [MAIN ] Completed service synchronization, ready to provide service. Jul 06 17:23:30.425 [2247] pcmk1 corosync notice [QUORUM] Sync members[1]: 1 Jul 06 17:23:30.425 [2247] pcmk1 corosync notice [TOTEM ] A new membership (1.1f) was formed. Members Jul 06 17:23:30.426 [2247] pcmk1 corosync notice [QUORUM] Members[1]: 1 Jul 06 17:23:30.426 [2247] pcmk1 corosync notice [MAIN ] Completed service synchronization, ready to provide service. Jul 06 17:23:34.809 [2247] pcmk1 corosync notice [QUORUM] Sync members[2]: 1 3 Jul 06 17:23:34.809 [2247] pcmk1 corosync notice [QUORUM] Sync joined[1]: 3 Jul 06 17:23:34.809 [2247] pcmk1 corosync notice [TOTEM ] A new membership (1.23) was formed. Members joined: 3 Jul 06 17:23:34.814 [2247] pcmk1 corosync notice [QUORUM] Sync members[3]: 1 2 3 Jul 06 17:23:34.814 [2247] pcmk1 corosync notice [QUORUM] Sync joined[2]: 2 3 Jul 06 17:23:34.814 [2247] pcmk1 corosync notice [TOTEM ] A new membership (1.27) was formed. Members joined: 2 Jul 06 17:23:34.821 [2247] pcmk1 corosync notice [QUORUM] This node is within the primary component and will provide service. Jul 06 17:23:34.821 [2247] pcmk1 corosync notice [QUORUM] Members[3]: 1 2 3 Jul 06 17:23:34.821 [2247] pcmk1 corosync notice [MAIN ] Completed service synchronization, ready to provide service.
And finally we get pcs to start the cluster, and we can verify it with crm_node -l:
[root@pcmk1 ~]# pcs cluster start
Starting Cluster...
[root@pcmk1 ~]# crm_node -l
1 pcmk1.svealiden.se member
2 pcmk2.svealiden.se member
3 pcmk3.svealiden.se member
Note that I’m switching between different nodes but since this is a cluster it doesn’t really matter which node I’m using to call pcs or other cluster-related functions.
Set a password for the hacluster user and authorize yourself against all nodes using that user:
[root@pcmk1 ~]# pcs host auth pcmk1.svealiden.se
Username: hacluster
Password:
pcmk1.svealiden.se: Authorized
[root@pcmk1 ~]# pcs host auth pcmk2.svealiden.se
Username: hacluster
Password:
pcmk2.svealiden.se: Authorized
[root@pcmk1 ~]# pcs host auth pcmk3.svealiden.se
Username: hacluster
Password:
pcmk3.svealiden.se: Authorized
[root@pcmk1 ~]# pcs cluster status
Cluster Status:
Cluster Summary:
* Stack: corosync
* Current DC: pcmk1.svealiden.se (version 2.1.0-0.2.rc1.fc34-b9ac0a9329) - partition with quorum
* Last updated: Tue Jul 6 17:51:19 2021
* Last change: Tue Jul 6 17:26:31 2021 by hacluster via crmd on pcmk1.svealiden.se
* 3 nodes configured
* 0 resource instances configured
Node List:
* Node pcmk3.svealiden.se: pending
* Online: [ pcmk1.svealiden.se pcmk2.svealiden.se ]
PCSD Status:
Warning: Some nodes are missing names in corosync.conf, those nodes were omitted
[root@pcmk1 ~]# pcs cluster start pcmk3.svealiden.se
pcmk3.svealiden.se: Starting Cluster...
[root@pcmk1 ~]# pcs cluster status
Cluster Status:
Cluster Summary:
* Stack: corosync
* Current DC: pcmk1.svealiden.se (version 2.1.0-0.2.rc1.fc34-b9ac0a9329) - partition with quorum
* Last updated: Tue Jul 6 17:51:36 2021
* Last change: Tue Jul 6 17:26:31 2021 by hacluster via crmd on pcmk1.svealiden.se
* 3 nodes configured
* 0 resource instances configured
Node List:
* Online: [ pcmk1.svealiden.se pcmk2.svealiden.se pcmk3.svealiden.se ]
PCSD Status:
Warning: Some nodes are missing names in corosync.conf, those nodes were omitted
It’s also good to set pcsd to start automatically(not a cluster command so this needs to be executed on each server individually):
But creating somewhat elaborate configurations isn’t super-easy. Let’s look at creating a MySQL cluster. I’m no expert on this but I’ll explain it as best I can.
First we have pcs cluster cib sveaha.xml which simply dumps the configuration of the cluster to an XML-file called sveaha.xml. We’ll make pacemaker store our changes in that file for now and then when we’re done we load it all into the running cluster as a single transaction.
Next pcs -f sveaha.xml resource create db_master_ip ocf:heartbeat:IPaddr2 ip=192.168.1.67 cidr_netmask=32 op monitor interval=30s on-fail=restart creates an IP-address 192.168.1.67 that we call db_master_ip. We’re not telling the cluster how and when to use it yet, merely that it exists and should use the IPaddr2 resource script from the ocf:heartbeat library.
Now the big one:
# pcs -f sveaha.xml resource create mysql ocf:heartbeat:mysql \ binary="/usr/bin/mysqld_safe" config="/etc/mysql/my.cnf" \ datadir="/var/lib/mysql" pid="/var/lib/mysql/mysql.pid" \ socket="/var/lib/mysql/mysql.sock" \ replication_user="replication_user" replication_passwd="MYPASSWORD" \ --master \ additional_parameters="--bind-address=0.0.0.0" op start timeout=60s \ op stop timeout=60s op monitor interval=20s timeout=30s \ on-fail=standby
This creates a mysql database resource named mysql based on the ocf:heartbeat:mysql resource script. We specify the path of the binary, the mysql config file, the directory that mysql should use to store the data files, what pid-file to use and what path should be used for the socket for local communication. Phew, next bit: we have to specify the replication user and the password used. The ocf:heartbeat:mysql script uses these values when turning server nodes into slave, executing queries like “CHANGE MASTER TO”. The –master part is very important and declares that this resource shall be divided into master/slave instances. Otherwise all nodes would be the same, either masters or slaves. Finally we say that the servers should listen for traffic intended for any IP-address(–bind-address=0.0.0.0) and give some reasonable values for starting, stopping and so on.
So far we’ve basically said that these MySQL instances should be present on all nodes but we need to be more precise. That’s the next bit: pcs -f sveaha.xml resource clone mysql clone-max=3 clone-node-max=1
This states that the mysql resource which is made up of clones should only have a total of three active clones at any time and no node should have more than one clone. My cluster has three nodes so maybe I could have skipped the clone-max setting but it seemed better to include.
What about that IP-address? pcs -f sveaha.xml constraint colocation add master mysql with db_master_ip score=INFINITY This states that the master mysql node and the db_master_ip should always be colocated on the same node, no exceptions. If the score is 5 and some other rule with score 6 says that the db_master_ip should be somewhere else, then it will win.
Finally, let’s state that the IP-address for the mysql master should be started until after the master node is ready: pcs -f sveaha.xml constraint order start mysql-master then db_master_ip
I also run three DNS-servers on these nodes and they aren’t divided into master/slave so the configuration looks slightly different:
So nothing here about –master or saying that the IP-address used to access the DNS-service has to be placed on a specific node. As long as some bind-clone runs on a node Pacemaker can put the IP-address there. But no IP-address is allowed to run on multiple nodes at the same time by design.
Let’s add some fencing. I rewrote the demonstration fencing-script that uses SSH to have my server hypervisors kill the cluster nodes. It’s not super-pretty but it works: https://deref.se/wp-content/uploads/2019/11/proxmox
You will need to set up passwordless SSH to the hypervisor nodes and place the script linked above in the directory for external scripts, on Ubuntu: /usr/lib/stonith/plugins/external/
To add these fencing devices to your Pacemaker-cluster:
This just says that the pcmk1 fencing device based on script external/pve shall fence the virtual machine with vmid 117 and that this has to be done on the Proxmox host pve1. The host list is what Pacemaker will look at when it tries to fence something. So pacemaker1.svealiden.se is now fenced by pcmk1 by running a command on Proxmox host pve1 using 117 as an argument to that command. Simiarly for pcmk2 and pcmk3. Finally we enable stonith(Shoot the Other Node in the Head) and load the configuration into the cluster.
I’ve been running a live MySQL and bind cluster like this for some months and by and large it works. I think I’m going to set Pacemaker to autostart itself on each node after power on though. By default it requires nodes to be started manually. One interesting and infuriating thing is that MySQL sometimes ends up with split brain requiring manual intervention. You can see if a slave is broken by running:
MariaDB [(none)]> SHOW SLAVE STATUS\G;
If you see error messages about duplicate keys and stuff, then you’re also in trouble. I don’t understand why this happens. I’ve read through the scripts used by Pacemaker and they all seem to make sense. If you’re sure nothing important got written to the node that Pacemaker can’t bring back into functioning slave-mode you can just delete everything in the MySQL data directory and create a blank template(example has node3 as a master, node2 as a broken slave that can’t catch up and node1 as a functioning slave):
Then import it into the blank MySQL install on the broken slave, making sure to start the MySQL instance yourself, not through Pacemaker:
node2 # systemctl start mysql node2 # mysql < dumpfromslave.sql
Next you need to manually get this node to catch up with the rest of the cluster before getting Pacemaker to manage the node. Not sure why this is but I spent hours with split brain issues even using this new “reset broken slave with SQL dump file” until I followed this advice. Let’s find out what the coordinates for synchronization were in the SQL dump file:
node2 # mysql MariaDB [(none)]> SHOW MASTER STATUS; +-------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +-------------------+----------+--------------+------------------+ | mysqld-bin.000015 | 328 | | | +-------------------+----------+--------------+------------------+ 1 row in set (0.00 sec)
Then run the whole command for making this node synchronize with the master:
> CHANGE MASTER '' TO MASTER_LOG_FILE='mysqld-bin.000015', MASTER_LOG_POS=328, MASTER_HOST='node3', MASTER_USER='replication_user', MASTER_PASSWORD='MYPASSWORD';
Note that in my example node2 was the broken slave, node1 was a functioning slave and node3 was the master. We didn’t get an SQL dump from node3 because that would lock tables, preventing writes. But once the dump was read into node2 we set it to synchronize data from node3. It is possible to get a slave to synchronize from a slave but Pacemaker will try to set things up with all slaves synchronizing from the master so that’s how I prepare node2.
With this done I can close the MySQL instance started via systemd and let Pacemaker take over again:
node2 # systemctl stop mysql node2 # pcs cluster start
This makes node2 start its own Pacemaker instance and join the cluster. Note that pcs status and pcs resource won’t tell you if MySQL slaves are running correctly, merely if they are live and labelled as slaves by Pacemaker. I use a Zabbix plugin to keep track of whether or not slaves are actually synchronizing. It warns “Slave SQL Not Running” if a slave isn’t keeping up with the master.
I’d like to try ClusterControl and MySQL Orchestrator at some point. We’ll see what time allows.
So I got fed up with Percona XtraDB Cluster some time back. It was the backend for Zabbix and a bad crash left me with a cluster that just wouldn’t form a quorum and that was it for me. Other problems had included lots of errors on commits due to inconsistencies between nodes which I felt was difficult to justify since only one of the nodes actually received any writes…
Well I have since written a python script that can write two multiple master servers compatible with MySQL. It complies with Percona’s Strict Mode and after some grinding I got it to maintain consistency of data. The code is absolutely awful but it works! One of the neat tricks is that it can at any point go through the database to determine that the “business logic” is maintained. That’s how I dug up tricky corner cases where a customer could have a purchase registered to him after he had been removed from the Customer-table.
So what happens when I run the script at full tilt(it’s not fast but 15-30 transactions per second isn’t bad given only three queries can run in parallel due to the aforementioned awful code) and I pull the plug on all three Percona XtraDB Cluster VMs? Well the script stops printing out information about completed operations because it can’t continue. So I kill the script.
Next I reboot all three nodes and they just automatically get back into working order. No fiddling with extraneous tables or having to set innodb_force_recovery. I was surprised. I’ve tried it a few times and it just works. Running the consistency-checker shows that atomicity has been maintained. I even took minute-by-minute snapshots of the mysql partition(running Btrfs) and forced a node back in time so it looked like it had lost five minutes of updates. Still no problem!
Now I find myself in the surprising position of having to roll up my sleeves and meticulously engineer a scenario to replicate what I once encountered in the wild. I will basically have to:
Reset the database back to a shared state X
Advance the cluster by writing from my script
Snapshot node 1
Reset the database back to the previous state X
Write some more
Snapshot node 2
Repeat for node 3
Eventually I will have three snapshots – one on each node – which constitutes a completely split brain. No quorum and no automatic syncing possible. Then I can test how to recover manually. Hmm,. I should probably snapshot all three nodes in each of the split brain versions. Then I can try a 2-1 situation and see how Percona XtraDB Cluster will handle it. It should let the 2 nodes that are in agreement start up but the 1 should be kept out, not resynced or overwritten – just excluded.
Well, that’s what I think anyway.
Addendum 1: Now something interesting happened for some reason. I had shut down the cluster cleanly and yet standard start via systemctl didn’t work:
root@pcmk1:~# systemctl start mysql Job for mysql.service failed because the control process exited with error code. See “systemctl status mysql.service” and “journalctl -xe” for details.
I had to cat the contents of /var/lib/mysql/data/grastate.dat to find the node with either the highest sequence number or safe_to_bootstrap: 1. I found the latter:
The other two nodes had the same seqno. Anyway, with this information in hand pcmk1 could be started with /etc/init.d/mysql bootstrap-pxc and then I could start the other two nodes with systemctl start mysql and then all was well again.
I’m getting the idea that the startup script for Percona XtraDB Cluster does some self-bootstrapping that isn’t just done by running systemctl start mysql. Or this is just one more mystery.
Notes to self: Point X: Snapshots/data/data@auto-2019-10-29-2111_48h Start of brain 1: Snapshots/data/data@auto-2019-10-29-2123_48h End of brain 1: Snapshots/data/data@auto-2019-10-29-2126_48h Start of brain 2: Snapshots/data/data@auto-2019-10-29-2134_48h End of brain 2: Snapshots/data/data@auto-2019-10-29-2137_48h Start of brain 3: Snapshots/data/data@auto-2019-10-29-2143_48h End of brain 3: Snapshots/data/data@auto-2019-10-29-2146_48h
Okey, testing brain 2 on pcmk3 and pcmk2 and let pcmk1 use brain 1. pcmk2 and pcmk3 had slightly different seqno which isn’t so weird since the snapshots can’t be initiated at the exact same microsecond and can’t really be expected to complete in exactly the same number of hard drive writes. So I had to edit the grastate.dat file for pcmk3 so that safe_to_bootstrap was set to 1 and then ran /etc/init.d/mysql bootstrap-pxc. I needed to run systemctl start mysql a couple of times to get pcmk2 to sync but eventually it got into place.
As expected pcmk1 couldn’t join and was left in its own partition. So far so good. Now to let each node use their own brain.
2019-10-30T21:21:22.923454Z 0 [Note] WSREP: Waiting for SST/IST to complete. 2019-10-30T21:21:22.923806Z 0 [Note] WSREP: STATE_EXCHANGE: sent state UUID: 390ca26a-fb5b-11e9-805a-9fd389d6c554 2019-10-30T21:21:22.924357Z 0 [Note] WSREP: STATE EXCHANGE: sent state msg: 390ca26a-fb5b-11e9-805a-9fd389d6c554 2019-10-30T21:21:22.924830Z 0 [Note] WSREP: STATE EXCHANGE: got state msg: 390ca26a-fb5b-11e9-805a-9fd389d6c554 from 0 (pxc-cluster-node-1) 2019-10-30T21:21:22.925159Z 0 [Note] WSREP: STATE EXCHANGE: got state msg: 390ca26a-fb5b-11e9-805a-9fd389d6c554 from 1 (pxc-cluster-node-2) 2019-10-30T21:21:22.925188Z 0 [ERROR] WSREP: gcs/src/gcs_group.cpp:group_post_state_exchange():324: Reversing history: 464082 -> 462077, this member has applied 2005 more events than the primary component.Data loss is possible. Aborting. 2019-10-30T21:21:22.925212Z 0 [Note] WSREP: /usr/sbin/mysqld: Terminated.
Seems reasonable. One node bailed out real quick but two kept trying.
But the cluster didn’t process queries during this attempt to form a quorum. Just as it intended. So let’s say we know for a fact that brain 3 is the “best”. Brain 1 and brain 2 are just wrong, not actually holding information that needs to be preserved. Percona XtraDB Cluster shouldn’t make this determination, as it hasn’t. But we need to be able to do this when we’ve reviewed the situation(and need to get things back up and running). So let’s run this on pcmk2:
rm -rf /var/lib/mysql/data/* systemctl start mysql
And the logic check passes when running my Python script. Okey, so let’s join the last node… And yeah, works the same. So if one is patient all you need to do is completely blank the datadir(which in my case is /var/lib/mysql/data but for most people will be /var/lib/mysql) and start the node again. It will do state transfer to initialize itself and then join.
What to do if you have a split brain scenario and no node is actually “wrong” but there actually is a discrepancy in valuable data? Well then you’re boned! Databases do not have a convenient way of merging data like that. I’m of the opinion that any application that writes to a database should have some fallback mechanism whereby it can scan versions of the database that diverged away from the master and then inject the changes into the master.
In my dummy application this would involve retrieving all purchases and all deposits of credit from the diverged copy. Any purchase or deposit of credit unique to the diverged copy would then be processed as if though they were brand new transactions coming in from customers, with the customers’ credit balance being changed accordingly. In some systems this may not be possible but it’s really a desirable feature when you don’t want a split brain to be an insurmountable obstacle to getting your records straight.
For process 2021 and all its child processes, trace system calls and place them in files with names like strace.pid (that’s the -ff part). Include 1000 bytes of data per call(-s 1000) and let each call be marked with wall clock time(-tt).
strace -p 2021 -T -o strace.log
Trace process 2021 and mark each call by the time it took between start and end of the call. Log it to strace.log.