It’s been two days now and I feel like this lady (from an interesting article at cnet who are apparently still in business). But now I got a MariaDB master-slave cluster set up through pacemaker. I thought it was going to be a breeze since I wrote down how to do it for MySQL 5.7 on this very website! But no…
First off, the resource agent which worked for MySQL 5.7 does _not_ seem to work for MariaDB 10.x. And pulling in the latest scripts from the clusterlabs Github repo into the correct folder in an Ubuntu 20.04-install is bananas. So I abandoned my dear testbench and installed Fedora 33 because their resource-agents package seemed to contain the right stuff. And they do!
But the documentation has some catching up to do. For my three nodes pacemaker01, pacemaker02, pacemaker03 the following sets up the cluster correctly once I set the same password for the hacluster-user on all nodes:
pcs host auth pacemaker01 pacemaker02 pacemaker03
pcs cluster setup mariaha pacemaker01 pacemaker02 pacemaker03
Note that this either requires that the hostnames can be resolved to the correct IPs on all three nodes. I did this through /etc/hosts since it’s a testbench.
You’ll also need these packages:
yum install pacemaker pacemaker-cli mariadb-server
Here’s my MariaDB conf file for pacemaker01:
[mariadb]
log-bin
server_id=1
log-basename=pacemaker01
binlog-format=mixed
expire_logs_days=2
relay_log_purge=0 # I want relay logs in case I need to debug duplicate entries etc.
relay_log_space_limit=1094967295 # But only like 1 GB of relay logs.
read-only=1 # Best to start in read-only mode by default to avoid duplicate entries accidents
I got some weird synchronization errors when the mysql-database was included in the replication so I tried locking replication down to this one database “sysbench”. log_bin=something is important for binary logging to be enabled and that’s a prerequisuite for replication. Obviously server_id needs to be unique to each server and pacemaker01 is replaced by the hostname of the other two servers in their conf-file.
pcs cluster cib mariadb_cfg
pcs -f mariadb_cfg resource create db_primary_ip ocf:heartbeat:IPaddr2 ip=192.168.1.209 cidr_netmask=21 op monitor interval=30s on-fail=restart
pcs -f mariadb_cfg resource create mariadb_server ocf:heartbeat:mariadb binary="/usr/libexec/mysqld" \
replication_user="replication_user" replication_passwd="randompassword" \
node_list="pacemaker01 pacemaker02 pacemaker03" \
op start timeout=120 interval=0 \
op stop timeout=120 interval=0 \
op promote timeout=120 interval=0 \
op demote timeout=120 interval=0 \
op monitor role=Master timeout=30 interval=10 \
op monitor role=Slave timeout=30 interval=20 \
op notify timeout="60s" interval="0s"
pcs -f mariadb_cfg resource promotable mariadb_server master-max=1 master-node-max=1 clone-max=3 clone-node-max=1 notify=true
pcs -f mariadb_cfg constraint colocation add master mariadb_server-clone with db_primary_ip score=INFINITY
pcs -f mariadb_cfg constraint order promote mariadb_server-clone then db_primary_ip symmetrical=true
pcs cluster cib-push mariadb_cfg
Here’s a nice thing: the command for creating a master-slave setup used to be something like “pcs -f mariadb_cfg resource master mariadb_server master-max=1 master-node-max=1 clone-max=3 clone-node-max=1 notify=true“
Yeah, the word master has been replaced by “promotable”. MariaDB are also working to expunge politically incorrect language in case you were wondering. Here was me thinking that slavery was a problem when applied to humans but I guess we’ll just purge these terms no matter what they refer to.
So anyway… What took all sunday was to figure out why pacemaker kept saying that zero nodes participated in the election of a new master. There were clearly three nodes registered as Online in the cluster. After equipping the file /usr/lib/ocf/resource.d/heartbeat/mariadb with some additional debug statements it became clear that the issue was that none of the servers were announcing their gtid_current_pos. Admittedly, that makes it difficult to elect which server is most advanced and should be promoted.
For whatever reason my practice of dumping the master DB like so:
mysqldump --master-data -A > master.sql
is okey but I neglected to consider that Pacemaker assumes that the “gtid_current_pos” value is usable. But this doesn’t get updated until after the replication gets going. So this ended up in the log:
Dec 13 21:14:17 mariadb(mariadb_server)[43240]: INFO: Value to be set as gtid for pacemaker03: 0-1-1
Set r/w permissions for uid=189, gid=189 on /var/log/pacemaker/pacemaker.log
Dec 13 21:14:17 mariadb(mariadb_server)[43240]: INFO: /usr/sbin/attrd_updater -p -N pacemaker03 -n mariadb_server-gtid -Q
Set r/w permissions for uid=189, gid=189 on /var/log/pacemaker/pacemaker.log
Dec 13 21:14:17 mariadb(mariadb_server)[43240]: INFO: Result: name="mariadb_server-gtid" host="pacemaker03" value=""
Set r/w permissions for uid=189, gid=189 on /var/log/pacemaker/pacemaker.log
Dec 13 21:14:17 mariadb(mariadb_server)[43240]: INFO: Query result: name="mariadb_server-gtid" host="pacemaker01" value="0-1-1"
Dec 13 21:14:17 mariadb(mariadb_server)[43240]: INFO: Value in read_gtid: 0-1-1
Set r/w permissions for uid=189, gid=189 on /var/log/pacemaker/pacemaker.log
Dec 13 21:14:17 mariadb(mariadb_server)[43240]: INFO: Query result: name="mariadb_server-gtid" host="pacemaker02" value=""
Dec 13 21:14:17 mariadb(mariadb_server)[43240]: INFO: Value in read_gtid:
Dec 13 21:14:17 mariadb(mariadb_server)[43240]: INFO: No reply from pacemaker02
Set r/w permissions for uid=189, gid=189 on /var/log/pacemaker/pacemaker.log
Dec 13 21:14:17 mariadb(mariadb_server)[43240]: INFO: Query result: name="mariadb_server-gtid" host="pacemaker03" value=""
Dec 13 21:14:17 mariadb(mariadb_server)[43240]: INFO: Value in read_gtid:
Dec 13 21:14:17 mariadb(mariadb_server)[43240]: INFO: No reply from pacemaker03
Dec 13 21:14:17 mariadb(mariadb_server)[43240]: INFO: Not enough nodes (1) contributed to select a master, need 3 nodes.
But by logging in to the slaves and running SET GLOBAL gtid_slave_pos=’0-1-1′; and then “START SLAVE;” did the trick.
A few quick restarts(both pull-the-plug style and orderly) later it seems to work fine. The problem I encountered before was that a master could not rejoin the cluster automatically after it was demoted, even if it was done nicely with “pcs cluster stop pacemaker01“. There would be “Failed to replicate, duplicate entry yada-yada” errors.
Not seeing that now, which is nice! I’ll rewrite my own sysbench script with transactions and “SELECT X FROM Y FOR UPDATE” and things that strain the DB a bit more to work with MariaDB and do some more tests.
Oh, for some reason the ocf:heartbeat:mariadb-script enables semi-synchronous replication for some reason. You might want to edit that segment(search for rpl_semi) if you don’t want that tradeoff.
Update 2021-07-08
Went through this again for some ProxySQL-testing and ended up writing a bash-script for setting up the whole thing with fencing and all:
#!/bin/bash
# Create a virtual IP for the database cluster
pcs -f mariadb_cfg resource create db_primary_ip ocf:heartbeat:IPaddr2 ip=192.168.1.180 cidr_netmask=21 op monitor interval=30s on-fail=restart
# Create the MariaDB clone on all three nodes
pcs -f mariadb_cfg resource create mariadb_server ocf:heartbeat:mariadb binary="/usr/sbin/mysqld" \
replication_user="replication_user" replication_passwd="REPLICATIONPASSWORD" \
node_list="pcmk1.svealiden.se pcmk2.svealiden.se pcmk3.svealiden.se" \
op start timeout=120 interval=0 \
op stop timeout=120 interval=0 \
op promote timeout=120 interval=0 \
op demote timeout=120 interval=0 \
op monitor role=Master timeout=30 interval=10 \
op monitor role=Slave timeout=30 interval=20 \
op notify timeout="60s" interval="0s"
echo MariaDB Server clone set created
# Indicate that there must only ever be one(1) master among the MariaDB clones
pcs -f mariadb_cfg resource promotable mariadb_server master-max=1 master-node-max=1 clone-max=3 clone-node-max=1 notify=true
# The virtual IP MUST be on the same node as the MariaDB master
pcs -f mariadb_cfg constraint colocation add master mariadb_server-clone with db_primary_ip score=INFINITY
pcs -f mariadb_cfg constraint order promote mariadb_server-clone then db_primary_ip symmetrical=true
echo MariaDB Server clone set constraints set
# Let pcmk1.svealiden.se be fence by the fence_pve agent that needs to connect to
# 192.168.1.21 with the provided credentials to kill VM 139(pcmk1)
pcs -f mariadb_cfg stonith create p_fence_pcmk1 fence_pve \
ip="192.168.1.21" nodename="pve1.svealiden.se" \
login="root@pam" password="PROXMOXROOTPASSWORD" plug="139" delay="15" vmtype="qemu" \
pcmk_host_list="pcmk1.svealiden.se" \
op monitor interval="60s" \
meta target-role="Started" is-managed="true"
pcs -f mariadb_cfg stonith create p_fence_pcmk2 fence_pve \
ip="192.168.1.22" nodename="pve2.svealiden.se" \
login="root@pam" password="PROXMOXROOTPASSWORD" plug="140" delay="15" vmtype="qemu" \
pcmk_host_list="pcmk2.svealiden.se" \
op monitor interval="60s" \
meta target-role="Started" is-managed="true"
pcs -f mariadb_cfg stonith create p_fence_pcmk3 fence_pve \
ip="192.168.1.23" nodename="pve3.svealiden.se" \
login="root@pam" password="PROXMOXROOTPASSWORD" plug="141" delay="15" vmtype="qemu" \
pcmk_host_list="pcmk3.svealiden.se" \
op monitor interval="60s" \
meta target-role="Started" is-managed="true"
echo Fence devices created
# Make sure each fencing device is located away from the node it is supposed to
# fence. It makes no sense to expect a node to be able to fence itself in the event
# of some malfunction.
pcs -f mariadb_cfg constraint location p_fence_pcmk1 avoids pcmk1.svealiden.se=INFINITY
pcs -f mariadb_cfg constraint location p_fence_pcmk2 avoids pcmk2.svealiden.se=INFINITY
pcs -f mariadb_cfg constraint location p_fence_pcmk3 avoids pcmk3.svealiden.se=INFINITY
echo Fence location constraints added
# Activate fencing
pcs -f mariadb_cfg property set stonith-enabled=true
pcs cluster cib-push mariadb_cfg
Had to increase the rights of the replication_user for some reason(I gave it SUPER for the sake of simplicity).
Oh, a nicer mysqldump variant:
mysqldump -A --single-transaction --gtid --master-data=1 --triggers --events --routines > pcmk2.sql
Update 2021-07-30
pcs cluster move for master doesn’t work in the latest Fedora due to promoted/master inconsistency between crm_resource and pcs. How surprising that changing keywords used to describe specific states causes problems… Anyway, this works:
[root@pcmk2 ~]# crm_resource --move --resource mariadb_server-clone --node pcmk1.svealiden.se --promoted --lifetime=P300S
Migration will take effect until: 2021-07-30 00:38:26 +02:00
[root@pcmk2 ~]# pcs constraint list --full
Location Constraints:
Resource: mariadb_server-clone
Constraint: cli-prefer-mariadb_server-clone
Rule: boolean-op=and score=INFINITY (id:cli-prefer-rule-mariadb_server-clone)
Expression: #uname eq string pcmk1.svealiden.se (id:cli-prefer-expr-mariadb_server-clone)
Expression: date lt 2021-07-30 00:38:26 +02:00 (id:cli-prefer-lifetime-end-mariadb_server-clone)
Resource: p_fence_pcmk1
Disabled on:
Node: pcmk1.svealiden.se (score:-INFINITY) (id:location-p_fence_pcmk1-pcmk1.svealiden.se--INFINITY)
Resource: p_fence_pcmk2
Disabled on:
Node: pcmk2.svealiden.se (score:-INFINITY) (id:location-p_fence_pcmk2-pcmk2.svealiden.se--INFINITY)
Resource: p_fence_pcmk3
Disabled on:
Node: pcmk3.svealiden.se (score:-INFINITY) (id:location-p_fence_pcmk3-pcmk3.svealiden.se--INFINITY)
Ordering Constraints:
promote mariadb_server-clone then start db_primary_ip (kind:Mandatory) (id:order-mariadb_server-clone-db_primary_ip-mandatory)
Colocation Constraints:
mariadb_server-clone with db_primary_ip (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-mariadb_server-clone-db_primary_ip-INFINITY)
Ticket Constraints:
[root@pcmk2 ~]# pcs resource
* db_primary_ip (ocf::heartbeat:IPaddr2): Started pcmk1.svealiden.se
* Clone Set: mariadb_server-clone [mariadb_server] (promotable):
* Masters: [ pcmk1.svealiden.se ]
* Slaves: [ pcmk2.svealiden.se pcmk3.svealiden.se ]
Update 2021-08-23
Forgot to include a really fast way of creating a new clone. No need for mysqldump or locking the source DB:
mariabackup -u root --backup --stream=xbstream | ssh NEWSLAVE "mbstream -x -C /var/lib/mysql/data"
Then chown -R mysql: /var/lib/mysql/data and using the output from the mariabackup command
[00] 2021-08-23 20:40:11 ...done
[00] 2021-08-23 20:40:11 Executing FLUSH NO_WRITE_TO_BINLOG ENGINE LOGS...
[00] 2021-08-23 20:40:11 mariabackup: The latest check point (for incremental): '5352582709'
[00] 2021-08-23 20:40:11 >> log scanned up to (5356297811)
mariabackup: Stopping log copying thread
[00] 2021-08-23 20:40:11 >> log scanned up to (5356297811)
[00] 2021-08-23 20:40:11 Executing BACKUP STAGE END
[00] 2021-08-23 20:40:11 All tables unlocked
[00] 2021-08-23 20:40:11 Streaming ib_buffer_pool to <STDOUT>
[00] 2021-08-23 20:40:11 ...done
[00] 2021-08-23 20:40:11 Backup created in directory '/root/xtrabackup_backupfiles/'
[00] 2021-08-23 20:40:11 MySQL binlog position: filename 'pacemaker01-bin.000007', position '968336', GTID of the last change '0-2-59839204,1-1-176656'
[00] 2021-08-23 20:40:11 Streaming backup-my.cnf
[00] 2021-08-23 20:40:11 ...done
[00] 2021-08-23 20:40:11 Streaming xtrabackup_info
[00] 2021-08-23 20:40:11 ...done
[00] 2021-08-23 20:40:11 Redo log (from LSN 5352582709 to 5356297811) was copied.
[00] 2021-08-23 20:40:11 completed OK!
Then log on to the new slave CHANGE MASTER TO MASTER_HOST=’pacemaker01.svealiden.se’, MASTER_USER=’replication_user’, MASTER_PASSWORD=’SECRETREPLICATIONPASSWORD’, MASTER_PORT=6603, MASTER_LOG_FILE=’pacemaker01-bin.000007′, MASTER_LOG_POS=968336;
Update 2021-08-23 – part 2
Running things and promoting and demoting nodes seems to be working fine. Consistency has thus far been maintained, which was otherwise the big issue the last time I ran an MariaDB Pacemaker cluster. read_only = ON in the config file is probably the number one contributor but maybe the dedicated MariaDB resource agent also plays a role.
Update 2021-08-29
New config for setting up fencing:
pcs cluster cib > conf_old
cp conf_old fence_cfg
# Let pacemaker01.svealiden.se be fence by the fence_pve agent that needs to connect to
# 192.168.1.21 with the provided credentials to kill VM 127(pacemaker01.svealiden.se)
pcs -f fence_cfg stonith create p_fence_pacemaker01 fence_pve \
ip="192.168.1.21" nodename="pve1" \
login="root@pam" password="PROXMOXPASSWORD" plug="127" delay="15" vmtype="qemu" \
pcmk_host_check="static-list" pcmk_host_list="pacemaker01.svealiden.se" \
op monitor interval="60s" \
meta target-role="Started" is-managed="true"
pcs -f fence_cfg stonith create p_fence_pacemaker02 fence_pve \
ip="192.168.1.22" nodename="pve2" \
login="root@pam" password="PROXMOXPASSWORD" plug="128" delay="15" vmtype="qemu" \
pcmk_host_check="static-list" pcmk_host_list="pacemaker02.svealiden.se" \
op monitor interval="60s" \
meta target-role="Started" is-managed="true"
pcs -f fence_cfg stonith create p_fence_pacemaker03 fence_pve \
ip="192.168.1.23" nodename="pve3" \
login="root@pam" password="PROXMOXPASSWORD" plug="129" delay="15" vmtype="qemu" \
pcmk_host_check="static-list" pcmk_host_list="pacemaker03.svealiden.se" \
op monitor interval="60s" \
meta target-role="Started" is-managed="true"
echo Fence devices created
# Make sure each fencing device is located away from the node it is supposed to
# fence. It makes no sense to expect a node to be able to fence itself in the event
# of some malfunction.
pcs -f fence_cfg constraint location p_fence_pacemaker01 avoids pacemaker01.svealiden.se=INFINITY
pcs -f fence_cfg constraint location p_fence_pacemaker02 avoids pacemaker02.svealiden.se=INFINITY
pcs -f fence_cfg constraint location p_fence_pacemaker03 avoids pacemaker03.svealiden.se=INFINITY
echo Fence location constraints added
# Activate fencing
pcs cluster cib-push fence_cfg
Super-important details: the part pcmk_host_list=”pacemaker02.svealiden.se” is how Pacemaker figures out which fencing “device” can fence which node. But this is only done if pcmk_host_check=”static-list” . Otherwise Pacemaker tries to figure things out itself which I don’t necessarily object to but I feel more confident putting in the right values myself. Note for instance that my VMs don’t use FQDN names so pacemaker02.svealiden.se is actually called pacemaker02 in Proxmox.
nodename=”pve2″ has to be the correct name of the Proxmox host as the cluster knows it. More specifically, if you don’t provide nodename at all, Proxmox will try to find an SSL-cert under /etc/pve/nodes/pacemaker02.svealiden.se which is just all kinds of wrong:
root@pve3:~# ls -lh /etc/pve/nodes/pacemaker02.svealiden.se
ls: cannot access '/etc/pve/nodes/pacemaker02.svealiden.se': No such file or directory
Note that I might think of pve3 as pve3.svealiden.se but in the Proxmox GUI it’s just pve3. So nodename has to be exactly pve3. I spent a lot of time figuring out why things weren’t working only to find myself here:
Aug 29 21:49:42 pve3 pveproxy[3137968]: '/etc/pve/nodes/pve3.svealiden.se/pve-ssl.pem' does not exist!
So that was fun!
Now to another problem. The mariadb resource agent doesn’t understand gtids that involve more than one gtid domain for the purposes of figuring out which node should be elected master:
Aug 29 22:01:30 pacemaker02 pacemaker-attrd[80247]: notice: Setting mariadb_server-gtid[pacemaker02.svealiden.se]: 0-2-59851595,1-1-1672237 -> 0-2-59851595,1-1-1672310
Aug 29 22:01:30 pacemaker02 mariadb(mariadb_server)[124915]: INFO: Not enough nodes (1) contributed to select a master, need 2 nodes.
Aug 29 22:01:30 pacemaker02 pacemaker-execd[80246]: notice: mariadb_server_monitor_20000[124915] error output [ (standard_in) 1: syntax error ]
Aug 29 22:01:30 pacemaker02 pacemaker-execd[80246]: notice: mariadb_server_monitor_20000[124915] error output [ /usr/lib/ocf/resource.d/heartbeat/mariadb: line 276: [: : integer expression expected ]
Turns out line 276 is a utility function which compares numbers and it’s called by a function that compares gtids and apparently it doesn’t work so well when there are two gtids. So now I need to figure out how to purge the errant domain id. I’m leaning towards shutting down Pacemaker, stopping the slaves, blanking all gtid data from the master and then reinitialize the slaves.
Can I blank all GTID data? Oh, even better! I can blank the domain id I don’t want: https://jira.mariadb.org/browse/MDEV-12012
MariaDB [(none)]> SELECT @@global.gtid_binlog_state;
+--------------------------------------+
| @@global.gtid_binlog_state |
+--------------------------------------+
| 0-2-59851595,1-1-1678111,1-2-1678300 |
+--------------------------------------+
1 row in set (0.000 sec)
MariaDB [(none)]> SELECT @@global.gtid_binlog_state;
+--------------------------------------+
| @@global.gtid_binlog_state |
+--------------------------------------+
| 0-2-59851595,1-1-1678111,1-2-1678337 |
+--------------------------------------+
1 row in set (0.000 sec)
MariaDB [(none)]> SELECT @@global.gtid_binlog_state;
+--------------------------------------+
| @@global.gtid_binlog_state |
+--------------------------------------+
| 0-2-59851595,1-1-1678111,1-2-1678338 |
+--------------------------------------+
1 row in set (0.000 sec)
MariaDB [(none)]> FLUSH BINARY LOGS DELETE_DOMAIN_ID=(0);
Query OK, 0 rows affected (0.029 sec)
MariaDB [(none)]> SELECT @@global.gtid_binlog_state;
+----------------------------+
| @@global.gtid_binlog_state |
+----------------------------+
| 1-1-1678111,1-2-1678626 |
+----------------------------+
1 row in set (0.000 sec)
MariaDB [(none)]> SELECT @@global.gtid_binlog_state;
+----------------------------+
| @@global.gtid_binlog_state |
+----------------------------+
| 1-1-1678111,1-2-1678629 |
+----------------------------+
1 row in set (0.000 sec)
MariaDB [(none)]>
Seems to have worked. Switching on Pacemaker messed up the synchronization but after running good old mariabackup -u root –backup –stream=xbstream | ssh NEWSLAVE “mbstream -x -C /var/lib/mysql/data” got things back into the right groove.

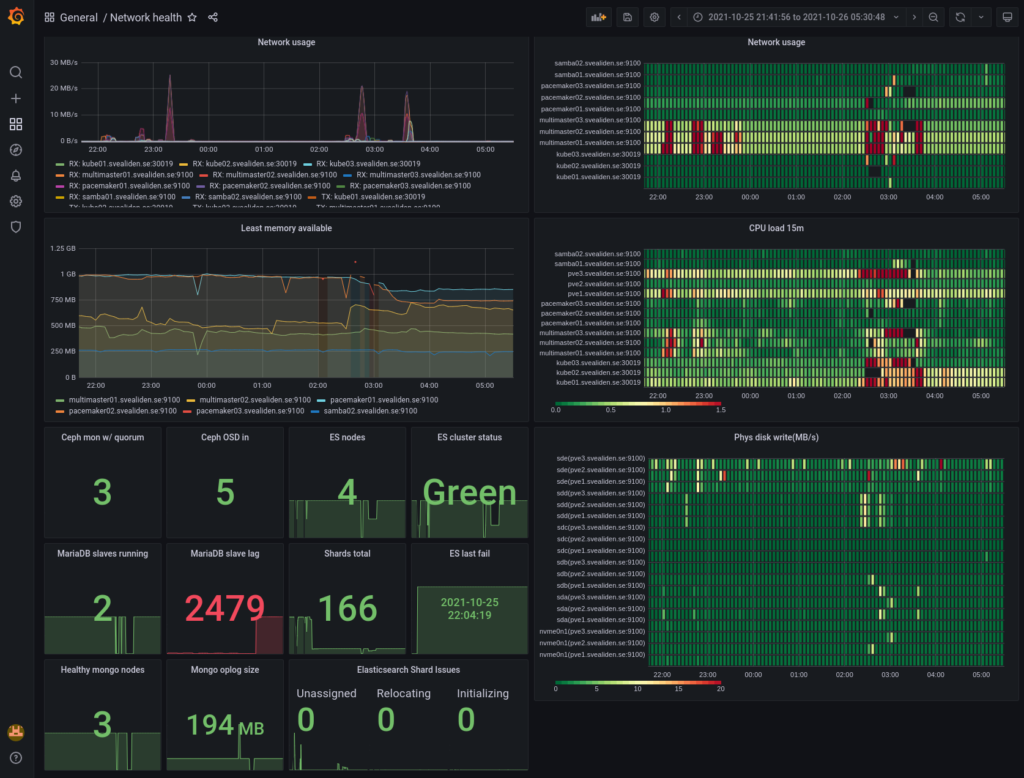


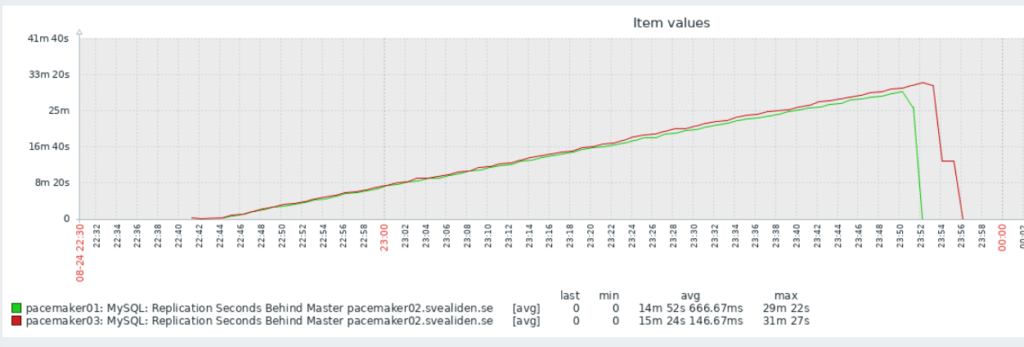



{kind=link}