I have some scripts to do switchover and failover between two MariaDB-instances that I use for everything from PowerDNS backend, Grafana configuration data, Zabbix, my own backup program and some more things I can’t remember off the top of my head. I used to use Pacemaker for that but encountered some strange behavior and chose to make my own so that I could follow the logic of the process, something which is difficult in Pacemaker.
The logic here is simple. mutex01 is the intended master and mutex02 is the intended slave. mutex02 runs a script for failover that fences mutex01 if it stops working correctly and then takes over the role of master. mutex01 does not run a similar script or we could end up in a fencing bonanza where both nodes keep killing each other. This could be handled by using three nodes and voting but that adds complexity that I don’t need.
(The names comes from mutual exclusion which is abbreviated mutex. In a MariaDB master/slave setup there can be only one master at any one time. So mutual exclusion must be maintained. This is different from multimaster-systems like MariaDB Galera(which I used to run and yes, these are nested parentheses) and things like Elasticsearch and MongoDB which I run on three servers called multimaster01, multimaster02 and multimaster03.)
The same set of scripts allows for switchover, using some files as flags to indicate that a change is being processed to keep the failover script for instance from going bananas. But this is kind of… not very easy to keep track of. I frequently forget to reset the flags which keeps the failover script from working. Enter my Python/Flask app that exports information about MariaDB and the flags of the scripts for each node and a React-frontend to view the data:

Each panel is its own React component which is given a hostname and intended role as arguments:

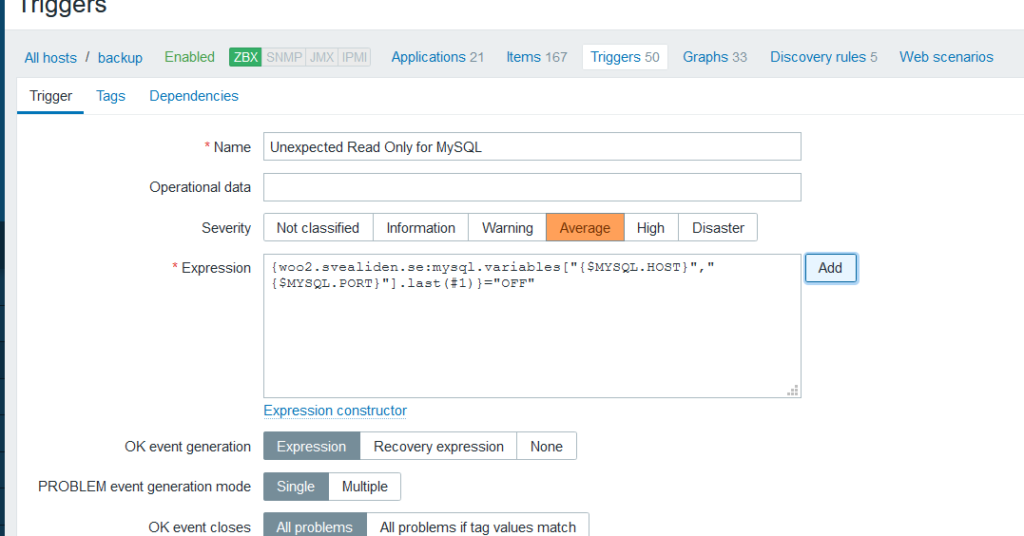
Based on this information the data can be highlighted based on how it conforms to the expected state of each server. For instance, after a failover has occurred we see that mutex02 is no longer in read-only mode which mutex01 is in read-only mode and is replicating data from mutex02. This is entirely correct after failover has occurred but it’s still a matter of the system being in a degraded state that I should inspect and fix.

Hmm, I should probably set red markings on Slave IO Running = No and Slave SQL Running = No for the slave node. (Making mental note that I will soon forget)
Anyway, we see that the failover-flag has been set on mutex02 to prevent it from doing any monitoring of mutex01, fencing or even writing to the failover-log(as indicated by the age ofthe log at the bottom of the mutex02-column). I reset the failover flag on mutex02 and check that seconds_behind_master was OK(it is marked as red if it is greater than the time the switchover-script is willing to wait for the nodes to be in sync before giving up) and then ran the switchover_to_here.sh-script on mutex01.

After clearing the maintenance flag on both nodes failover_log_age dropped and stayed low(the failover script runs for like 50 seconds starting once a minute and keeps outputting data so the timestamp of the failover-log is typically no more than 10 seconds during normal operations.
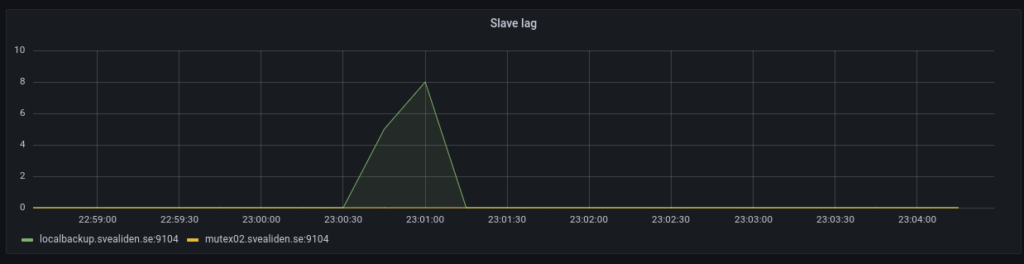
We can see how mutex01(green) stopped processing queries and how mutex02(yellow) took over and then how the switchover restored things in the Grafana graphs of Prometheus data:
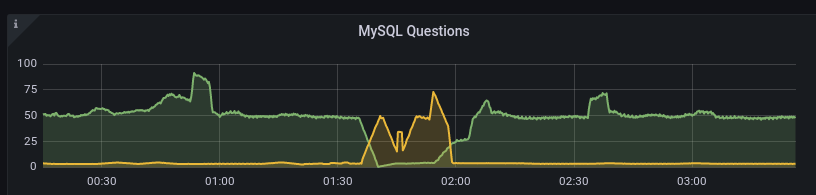
All in all I’m pretty pleased with how this worked out. I may publish the failover/switchover scripts and possibly also the Python/Flask-stuff. The React app however is way too hacky. Example:
class ServerStatus extends React.Component {
constructor(props) {
super(props)
this.state = {
error: null,
isLoaded: false,
failover_flag: null,
gtid_binlog_pos: null,
exec_master_log_pos: null,
gtid_position: null,
gtid_slave_pos: null,
last_io_errno: null,
last_sql_errno: null,
maintenance_flag: null,
position_type: null,
read_only: null,
relay_log_space: null,
seconds_behind_master: null,
slave_io_running: null,
slave_io_state: null,
slave_sql_running: null,
slave_transactional_groups: null,
failover_log_age: null
}
}
// {"exec_master_log_pos":5274471,"failover_flag":0,"gtid_binlog_pos":"1-11-40976726","gtid_position":"1-12-38358929",
// "gtid_slave_pos":"1-12-38358929","last_io_errno":0,"last_sql_errno":0,"maintenance_flag":0,"position_type":"Current_Pos",
// "read_only":0,"relay_log_space":309452,"seconds_behind_master":null,"slave_io_running":"No","slave_io_state":"",
// "slave_sql_running":"No","slave_transactional_groups":455}
fetchData = () => {
fetch('http://' + this.props.servername + '.svealiden.se:5000/')
.then((res) => res.json())
.then(
(result) => {
//alert("result:" + JSON.stringify(result));
this.setState({
isLoaded: true,
failover_flag: result['failover_flag'],
gtid_binlog_pos: result['gtid_binlog_pos'],
exec_master_log_pos: result['exec_master_log_pos'],
gtid_position: result['gtid_position'],
gtid_slave_pos: result['gtid_slave_pos'],
last_io_errno: result['last_io_errno'],
last_sql_errno: result['last_sql_errno'],
maintenance_flag: result['maintenance_flag'],
position_type: result['position_type'],I’m pretty sure this isn’t how you’re supposed to do it… But it beats not having continuously updated information on the state of a MariaDB pair with halfway complex rules on what is correct and what isn’t correct.
Note that since I started using this script for my actual “workloads” I’ve had like four or five failures that required me to resynchronize nodes after failover and even switchover! I struggled for hours to deal with extraneous transactions that messed up the GTID-sequences only to finally learn that if you have tables with Engine=MEMORY you always get “DELETE FROM tablename” added at startup of MariaDB. That adds an extra local operation that gets master and slave out of sync. So I’m not using MEMORY tables any more. They were only there to avoid write-tests straining my hard drives which was kind of silly anyway.
But now things seem to have settled down and not even yesterday’s failover required my to resynchronize nodes. That’s otherwise something you should expect, that failover leaves you with the old master node being out of sync with the slave that has now taken over the master-role temporarily. Switchover is different as we are just moving the master role between two functioning systems so we can bail out of the process if something doesn’t work out correctly, keeping the master as master. Example from my script for failover:
echo "Starting failover from $OTHERNODE to $THISNODE. $(date +%s)"
echo "1" > "/root/failovermode"
# Need to demote master if possible
my
if OTHERNODE_RO_MODE=$(mysql --connect-timeout=2 -N -s -B -h "$OTHERNODE" -B -N -e "SELECT @@GLOBAL.read_only;");
then
# If that worked we can check the return value
if [ "$OTHERNODE_RO_MODE" = "1" ];
then
# We can become master without an issue in an emergency,
# but we should ideally wait for this node to catch up.
echo "Other node is read_only now. Waiting for catchup. $(date +%s)"
wait_for_catchup
# Don't really care how we got out of wait for catchup, it's time to become master.
promote_local
elif [ "$OTHERNODE_RO_MODE" = "0" ];
then
echo "Failed to set $OTHERNODE to set read_only=1. Fencing!"
if fence_other_node;
then
# Can't catch up since we don't know the master GTID
echo "Fenced other node successfully. $(date +%s)"
promote_local
exit 0;
else
echo "Failed to fence master. Can't proceed. $(date +%s)"
exit 1;
fi # End fence_other_node check
else
echo "We received neither read_only=1 _or_ read_only=0. Shouldn't be possible."
fi # End second OTHERNODE check run after sending read_only=1
else
echo "Couldn't check if $OTHERNODE is read_only. Must fence! $(date +%s)"
if fence_other_node;
then
# Can't catch up since we don't know the master GTID
echo "Fenced other node successfully. $(date +%s)"
promote_local
exit 0;
else
echo "Failed to fence master. Can't proceed. $(date +%s)"
exit 1;
fi # End fence_other_node check
fi # End of check of return status from other node read_only-status
exit 1As you can see in the first nested if-statements we can wait for some time for the slave to catch up to the old master before promoting itself but we’re not going to wait indefinitely. We only failover if the master is slightly wonky so we can’t assume that the slave will always catch up(maybe the master sent back a bad GTID?). Same thing if we can’t even talk to the old master when failing over, we have no choice but to fence it. We wouldn’t know which GTID is the latest so saying “Let the old slave wait until it reaches GTID X before becoming master” makes no sense.
This has been a test of the audience’s patience.